Hébergement Haute-Disponibilité dédié pour Ruby on Rails - Paris On Rails - 17 novembre 2006
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Hébergement Haute-Disponibilité dédié pour Ruby on Rails Paris On Rails – 17 novembre 2006
Qu'est-ce que la haute disponibilité
● La Haute disponibilité consiste à mettre en
œuvre l'environnement nécessaire à un
fonctionnement le plus sûr possible.
– Prévention des fautes : Choix de l'infrastructure,
simplicité, surveillance et anticipation.
– Tolérance aux fautes
– Élimination des fautes : sysadmins compétents et
disponibles.
– Prévision des fautes : Planification et tests des
migrations, dialogue entre les développeurs et
sysadmins, documentation.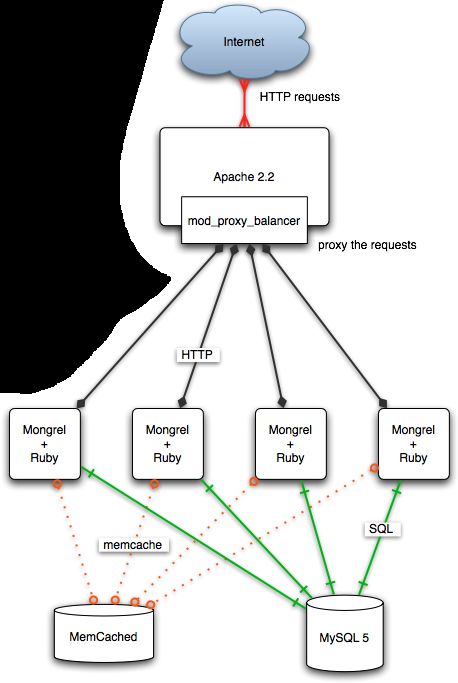
Bénéfices de l'approche Haute
Disponibilité
● La réduction des nuisances due aux pannes.
● L'augmentation de qualité de service.
● Une grande souplesse d'évolution :
– scalabilité
– changements technologies profonds aisés
● Un gain justifié de crédibilité auprès des
partenaires commerciaux.
Les points forts de Rails
● K.I.S.S.
– En privilégiant la simplicité, le développement
d'applications Ruby on Rails aide à la réduction des
erreurs humaines.
● Choix dans la gestion des sessions :
– Fichiers partagés par NFS
– Base SQL
– Memcached
● Facilité de déploiement sur de multiples serveurs
avec Capistrano
Quel serveur choisir ?
● Rails est utilisable dans différents
environnements et de multiples solutions valides
existent.
● Deux modèles co-existent, proxy HTTP vers
Mongrel et FastCGI.
Navigateurs Navigateurs
HTTP HTTP
HTTP HTTP
Serveurs Serveurs
Serveur HTTP Serveur HTTP
d'application d'application
Proxy HTTP Client FastCGI
Rails - Mongrel Rails - FastCGI
HTTP FastCGIApache/2.2 + mod_proxy_balancer +
Mongrel
● Facilité d'intégration à une infrastructure
existante
● Apache est incassable
● Tout sysadmin connaît Apache
● La moins performante
● Développement d'Apache fiable mais lentLightTPD, nginx
● Serveurs HTTP au moins 3x plus rapides
qu'Apache2 sur les fichiers statiques.
● Configuration simple à définir, simple à
maintenir.
● Développeurs accessibles par Mailing-List, IRC,
très réactifs.
● Uploads dans nginx : fichier temporaire envoyé à
un serveur d'application fonctionnel.
Exemple : un déploiement Capistrano
n'interrompra pas un envoi de fichier en cours.FastCGI, Mongrel ?
● Les deux fonctionnent et sont stables.
● Utilisez FastCGI pour LightTPD < 1.5 :
Le proxy HTTP actuel n'est pas fiable.
● Lancement et gestion des processus FastCGI ou
Mongrel par Monit, qui les relancera en cas de
crash.
● Surveillance l'utilisation mémoire des processus
& crashs éventuels : déclenchement d'alertes.Choix du serveur : dans le temps
● Aucune des solutions n'est actuellement
disponible en paquet dans les distributions Linux
stables : nécessité de tester, compiler et tenir à
jour manuellement.
● L'approche Hautement Disponible permet de
basculer d'une solution à l'autre sans arrêt de
service.
● LightTPD 1.5 est extrêmement prometteur :
– Meilleur proxy HTTP
– backend linux-sendfile-aioChoix du serveur : conclusion
● LightTPD ou nginx pour les sites à fort trafic
statique (serveur de téléchargement, vidéos,
photos)
● Attention aux fuites de mémoires du serveur
HTTP ou de l'application Rails :
– LightTPD en a souffert sur certaines configurations.
– Mongrel réagit de manière inattendue dans
certaines applications sous une très forte charge.
● La bonne solution serveur est celle que les
sysadmins maîtrisent : la compréhension
influence directement la fiabilité.Qualité et optimisations de l'application
● Vérifier l'utilisation mémoire (attention aux
variables d'instance, aux globales)
● Modifier les pages demandant de trop longs
temps de calculs (rester < 1s) en utilisant
BackgrounDRb.
● Intégrer à la batterie de tests des benchmarks
avec ApacheBench et httperf, validant l'utilisation
mémoire et les performances.
Tester différentes URLs sous de nombreuses
connexions simultanées.
● Tester l'application sur tout les navigateurs.The adventures of scaling source : The adventures of scaling, Stage 4
Analyse :
The adventures of scaling
● Les modèles NFS et MySQL
sont bon
● Un oubli : le serveur NFS doit
lui même être Hautement
Disponible
● Une erreur, le frontal est un
proxy applicatif unique :
– C'est un point de panne.
– C'est un facteur limitant les
performances et les capacités
de mise à l'échelle.Scaling Rails with Apache 2.2, mod_proxy_balancer and Mongrel source : BlogFish - Jonathan Weiss
Analyse :
Scaling Rails with Apache 2.2,
mod_proxy_balancer and Mongrel
● Le modèle est identique à
Scale with Rails.
● On retrouve la même erreur, le
Single Point Of Failure
applicatif d'Apache.Besoin d'un meilleur modèle :
méthodes hautement disponibles
● Réduction du nombre d'intermédiaires de niveau
applicatif :
– Suppression de la limite de performances d'un
proxy unique.
● Pas d'ajout de bug dû à un proxy HTTP :
– Transparence totale de la couche HA.
● Failover (basculement) sur le frontal.
● Surveillance et envoi d'alertes depuis le frontal
actif.Présentation d'une solution Hautement
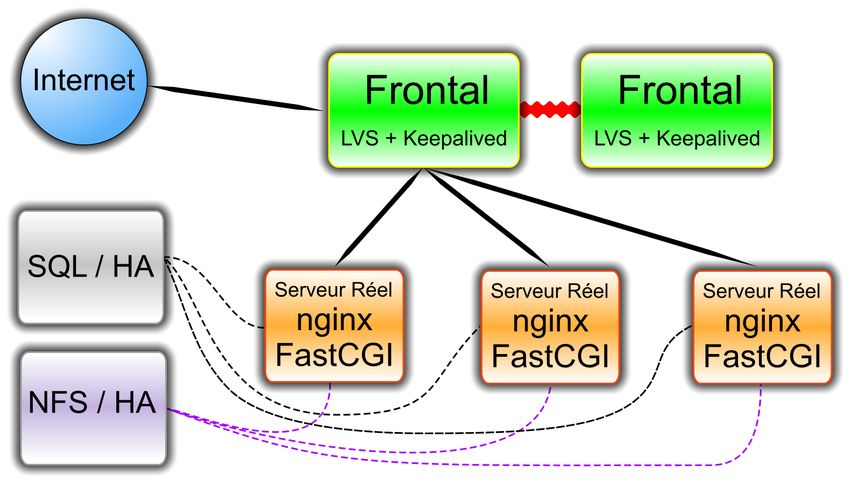
Disponible
● Frontaux : Linux Virtual Server + Keepalived
– LVS : intégré au noyau Linux 2.6
– Performances supportant aisément + de 100
serveurs réels.
– Totale indépendance vis à vis du protocole HTTP.
● Serveurs réels : machines indépendantes,
embarquant le serveur HTTP et le serveur
d'application Rails et ses fichiers.
● Serveur SQL Hautement Disponible
● Filer Hautement DisponibleVisuel d'une solution Haute Disponibilité
Évaluer le besoin d'un Filer :
serveur de fichiers NFS
1)Le site n'utilise que des fichiers déployés avec
l'application : pas de Filer.
– Déploiement distribué par Capistrano et
Subversion.
2)Le site met en ligne des contenus envoyés par
les visiteurs : utilisation d'un Filer.
– Uniformisation des accès aux fichiers.
– Performances élevées : seul le serveur HTTP entre
en jeu pour
● Les contenus statiques.
● Le cache statique html de Rails.Linux Virtual Server + Keepalived :
failover
● Le failover des frontaux permet de gagner un
répartiteur de charge sans créer de point de
panne.
● Le remplacement automatique d'un frontal par
son second est transparent :
– prend moins d'une seconde.
– préserve les connexions existantes grâce à une
communication entre les noyaux des frontaux.Linux Virtual Server + Keepalived :
répartition de charge
● Fonctionnalités de répartition :
– Répartie selon la puissance ou la charge des
serveur réel.
– Monitoring par hash d'URL HTTP(S), connexion
TCP ou personnalisé :
● Les serveurs réels déficients sont ajoutés ou enlevés du
groupe rapidement.
● Alertes Mail & logs
– Choix de l'algorithme de répartition de charge pour
maximiser les performances selon votre application.Les besoins matériels pour Rails HA
● Au moins 4 machines
● Les frontaux :
– 2 machines, de puissance indifférente, composées
de matériel éprouvé plutôt que moderne.
– Au moins 2 cartes réseau.
● Les serveurs réels :
– À partir de 2 machines.
– Bien équipés en RAM (au moins 2Go) :
● nombreux serveurs d'application simultanés
● large cache de fichiers.Les besoins matériels annexes
● Un ou des serveurs SQL HA :
– Assuré par réplication multi-maîtres ou failover.
● Un filer HA :
– Un NAS spécialisé, lui même redondant
– Solution économique : deux serveur NFS Linux
● failover HeartBeat
● synchronisation des données en temps réel par DRBD
● linux-raid sur des disques hotplug
● LVM pour l'abstraction de volumes et XFS pour étendre le
système de fichier à chaudFutur, en Vrac
● Zed Shaw, développeur hors-normes de Mongrel
envisage :
– A "mostly C" version for Unix only that's fast as
blazes.
– un remplaçant de mongrel_cluster
– un module nginx
● Une solution Haute Disponibilité vous permet
d'envisager sereinement les évolutions futures.
● La solution qui marche aujourd'hui est meilleure
que celle qui devrai marcher demain ;)Vos expériences
● Les retours d'expérience sont précieux :
À vous !
Auteur :
François Simond
Licence de cette présentation :
BSDVous pouvez aussi lire

















































