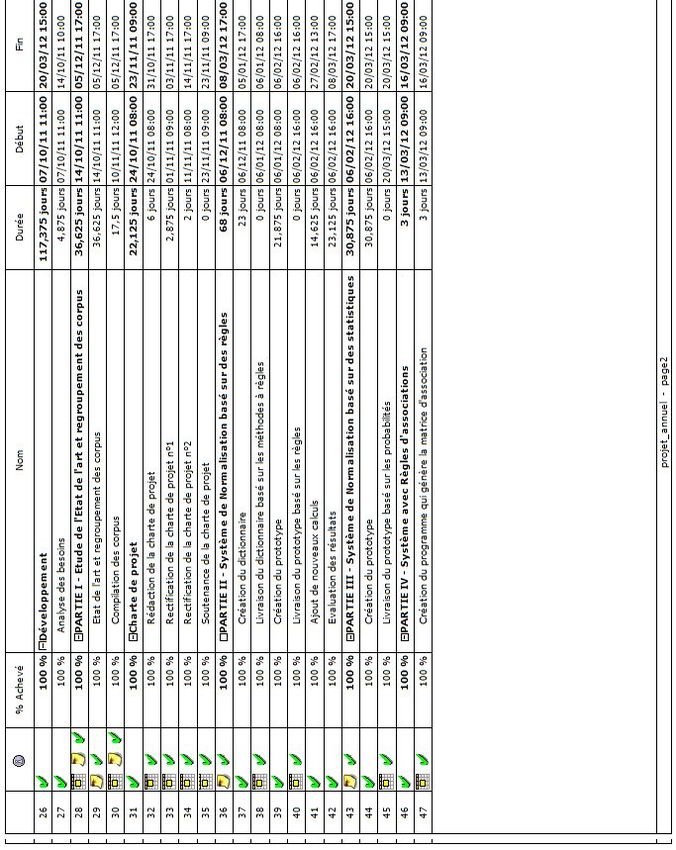
"SMS2TEXT" "Traduction Automatique du Langage SMS
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
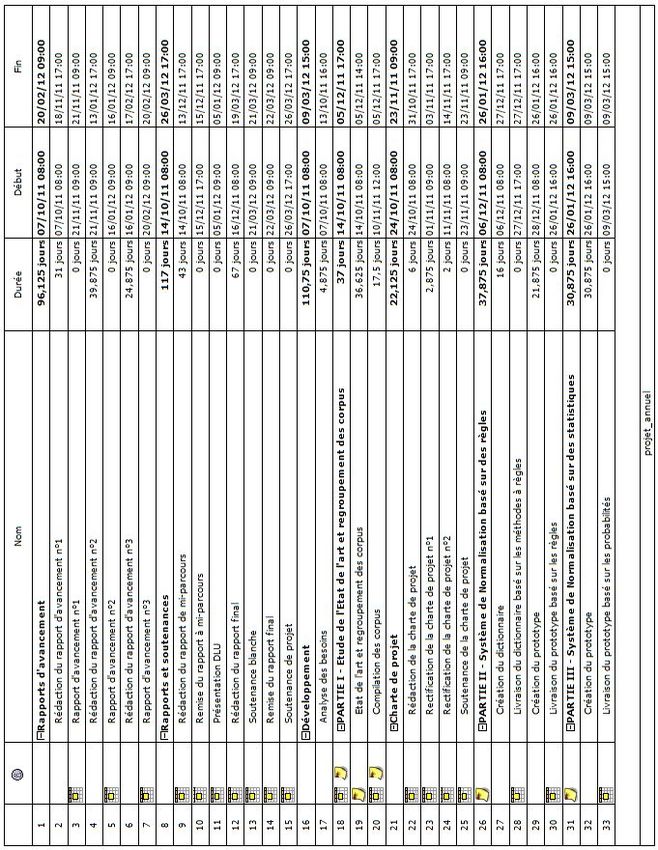
Université de Caen Basse-Normandie
Projet Annuel
"SMS2TEXT"
«Traduction Automatique du Langage SMS
vers la Langue Naturelle»
(Traduktion otomatik du langage SMS vr la lang naturL)
Membre du groupe :
Tuteur :
Emilie Lebossé
Gaël Dias
Pierre-Yves Lapersonne
21 mars 2012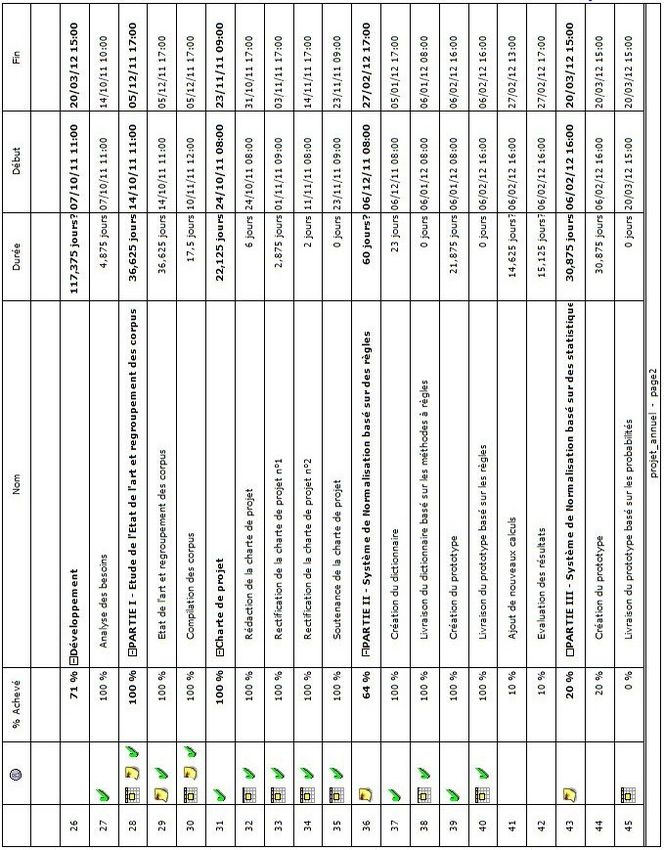
Remerciements
Tout d’abord, nous tenons à remercier vivement Gaël Dias, qui, en tant que tuteur, a su nous
consacrer une partie de son temps afin de nous guider tout au long du projet. De part ses ex-
plications, sa patience et l’aide qu’il a apportée, le projet a put finalement aboutir dans les temps.
Nous tenons également à remercier les différentes équipes de chercheurs qui ont put nous
envoyer sans contre partie une partie des résultats de leurs recherches afin de nous permettre
de réaliser nos propres corpora de SMS. Nous faisons référence ainsi aux membres de l’équipe
de l’Institute of Infocomm Research de Singapour (Aiti Aw, Min Zhang, Juan Xiao et Jian Su) [1]
pour les données concernant le corpus en anglais. Nous citons également l’équipe de chercheurs
de l’Université Chinoise de Hong Kong (Kam-Fai Wong et Yunqing Xia) [11] pour leur partici-
pation à l’élaboration du corpus de textes en chinois. Enfin, nous faisons également référence
aux membres d’une équipe de recherche d’Orange Labs Lannion qui a put nous fournir en
données afin de constituer notre corpus de textes français (Catherine Kobus, François Yvon et
Géraldine Damnati) [6].
Par ailleurs, nous tenons à remercier Adrien Lardilleux et Wigdan Abbas Mekki pour leurs
explications et l’aide qu’ils nous ont apportées à propos d’Anymalign et de Moses.
Enfin, nous voulons remercier Jean-Philippe Métivier pour sa participation au projet concer-
nant les règles d’associations. Ses explications claires ont pu nous faire avancer dans notre
système de traduction.
i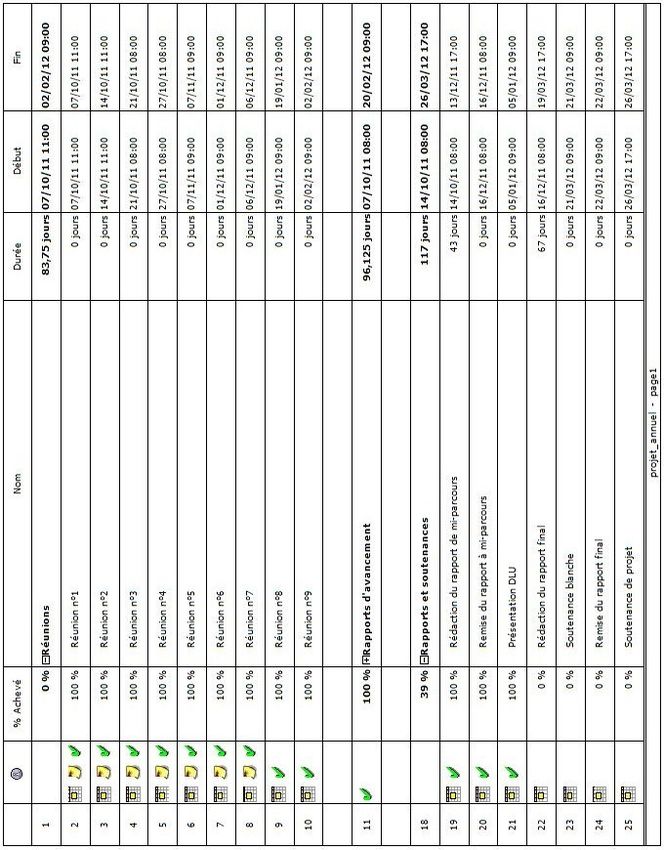
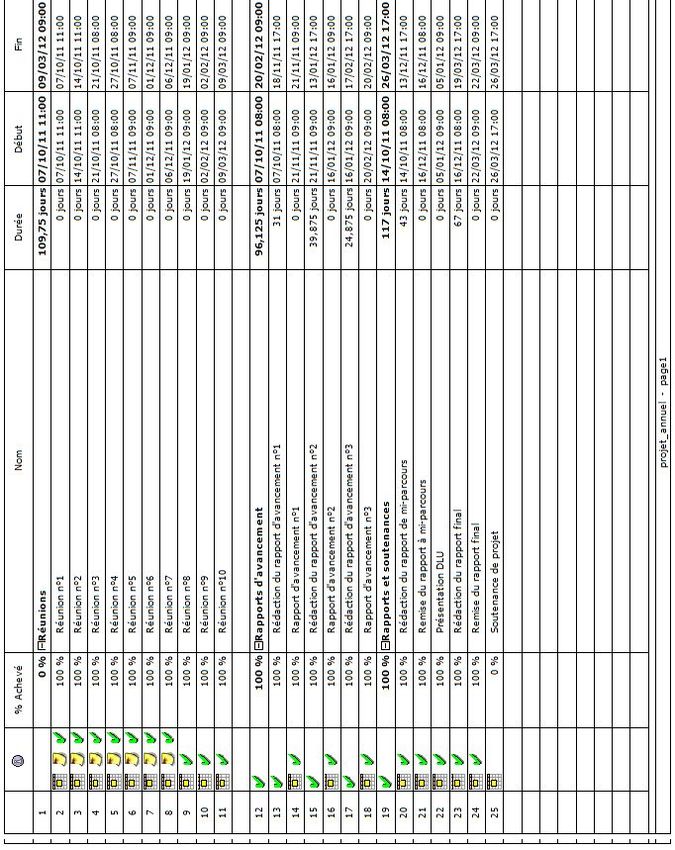
Table des matières
Remerciements i
Table des matières iii
Table des figures v
1 Introduction 1
1.1 Contexte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Objectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Contraintes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Etat de l’art 3
2.1 Caractéristiques Linguistiques du Langage SMS . . . . . . . . . . . . . . . . . . . 3
2.1.1 L’Abréviation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.2 Le Rébus typographique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.3 La Contraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.4 Les Émotions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.5 La Combinaison de Procédés . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Les Différents Modèles de Traduction Automatique . . . . . . . . . . . . . . . . . 6
2.2.1 Les Paradigmes Basés sur la Linguistique . . . . . . . . . . . . . . . . . . . 6
2.2.2 Les Paradigmes Basés sur les Statistiques . . . . . . . . . . . . . . . . . . . 8
2.3 La Traduction du Langage SMS au Langage Naturel . . . . . . . . . . . . . . . . . 9
2.4 Les Applications Existantes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Normalisation du Corpus 11
3.1 Le Métalangage XML et la Validation avec une DTD . . . . . . . . . . . . . . . . . 11
3.1.1 Qu’est ce que le XML ? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.1.2 La DTD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2 Les Corpora formatés en XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
iii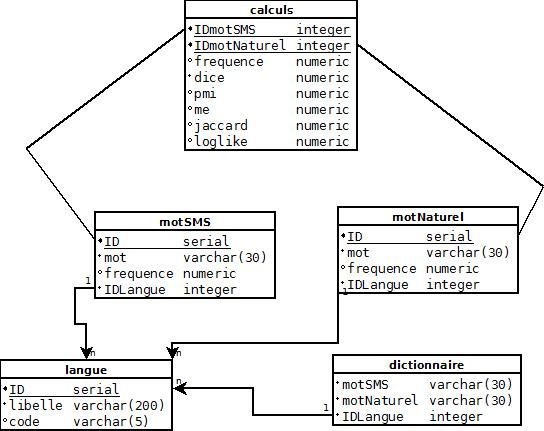
iv TABLE DES MATIÈRES
4 Traduction Basée sur des Règles 15
4.1 Création du Dictionnaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.1.1 La méthode de Smadja (1996) . . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.1.2 Le Dice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
4.1.3 Des calculs suplémentaires . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.2 Évaluation du Dictionnaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.3 Règles de Traduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
5 Traduction Basée sur des Modèles Statistiques 21
5.1 Anymalign . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5.2 Moses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
6 Développement 23
6.1 Traitement des données reçues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
6.2 Analyse de Système . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
6.3 Base de Données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
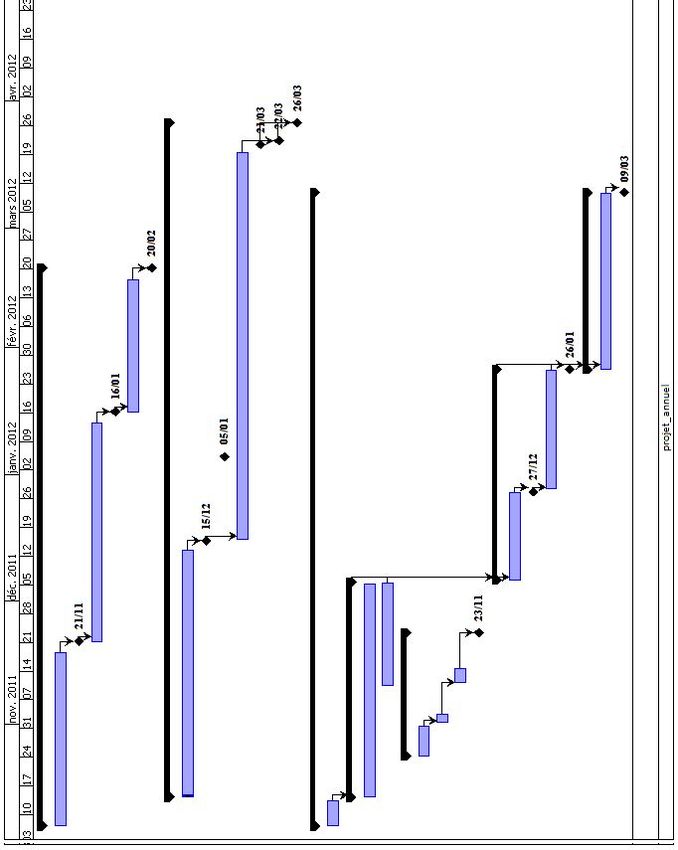
7 Déroulement du Projet 35
7.1 Les étapes du projet initiales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
7.2 Les étapes du projet effectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
8 Conclusions et Perspectives 37
9 Lexique 39
10 Annexes 41
Bibliographie 69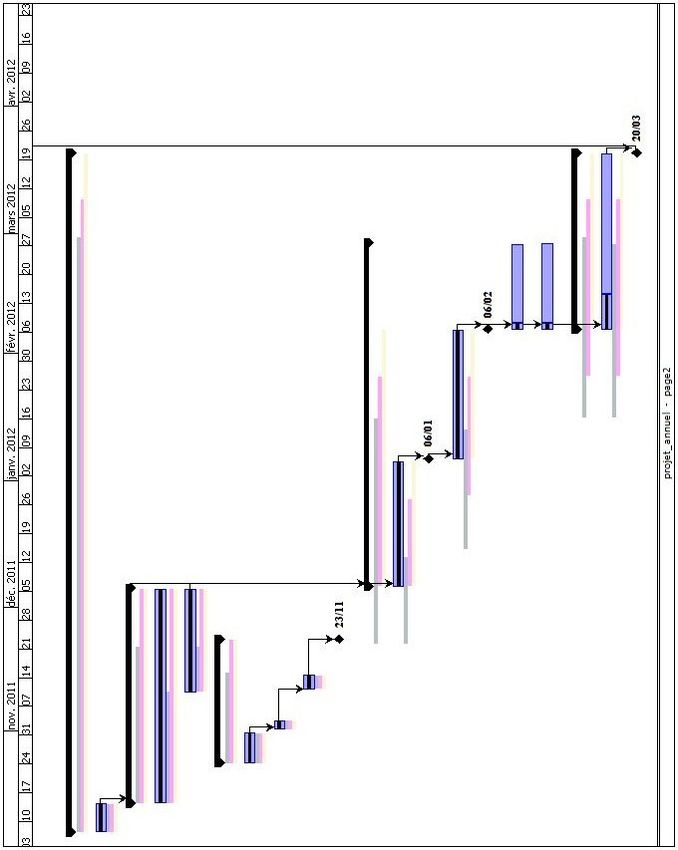
Table des figures
4.1 Schéma de la méthode de Smadja . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
6.1 Morceau du diagramme de classe du programme DictionnaireSMS . . . . . . . . 25
6.2 Morceau du diagramme de classe du programme TraducteurSMS . . . . . . . . . 27
6.3 Morceau du diagramme de classe du programme EvaluateurSMS . . . . . . . . . 29
6.4 MLD de la base de données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
1 Planning du projet initial (Liste des tâches) . . . . . . . . . . . . . . . . . . . . . . 51
2 Planning du projet initial (Gantt) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
3 Planning du projet initial (Liste des tâches 1) . . . . . . . . . . . . . . . . . . . . . 53
4 Planning du projet initial (Liste des tâches 2) . . . . . . . . . . . . . . . . . . . . . 54
5 Planning du projet initial (Diagramme 1) . . . . . . . . . . . . . . . . . . . . . . . 55
6 Planning du projet initial (Diagramme 2) . . . . . . . . . . . . . . . . . . . . . . . 56
v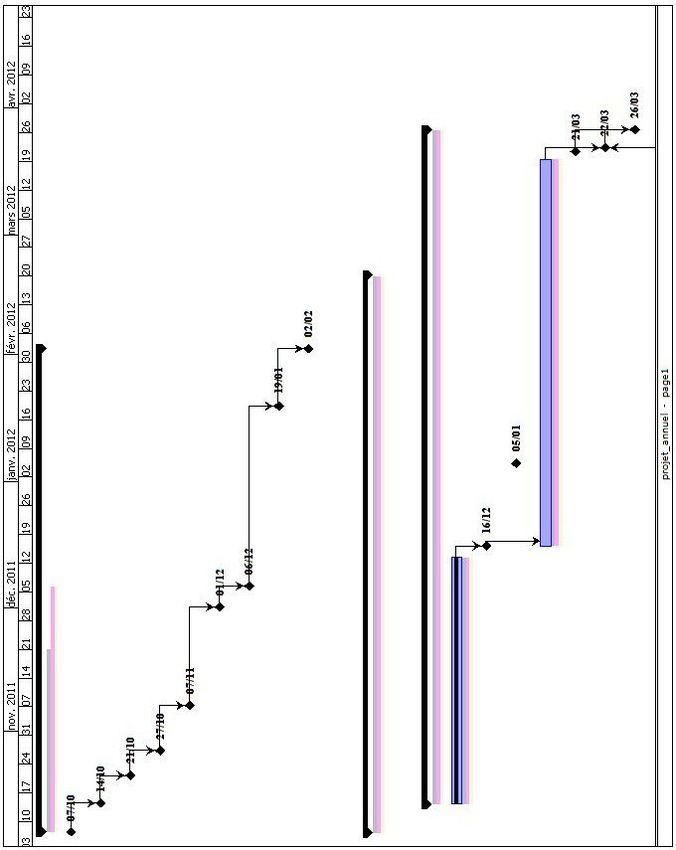
Chapitre 1
Introduction
Le marché du smartphone est en pleine expansion depuis 2010 dû à l’apparition de nou-
veaux appareils comme l’Iphone (Apple), les Blackberry (RIM), et les dispositifs sous Android
(Google). Néanmoins une grande partie de la population est « info-exclue » car elle ne se sent
pas intéressée ou n’est pas initiée à ces technologies de communication. L’utilisation de ces
appareils est à l’origine d’un nouveau langage le SMS (Short Message Service). Celui-ci consiste
à réduire un texte en langue naturelle en utilisant par exemple des abréviations ou la phonétisa-
tion des mots. Cependant ce langage n’est pas normalisé et il n’est employé que par une partie
des utilisateurs. De plus de nouvelles règles sont continuellement inventées ce qui le rend très
dynamique. Cela a pour effet de rendre sa compréhension difficile. Nous essaierons donc de
répondre à la question suivante : « Comment réaliser un outil proposant une traduction efficace
du langage SMS au langage naturel dans différentes langues ? ».
1.1 Contexte
Les technologies de communication mobiles sont essentiellement basées sur un service
d’échange de messages écrits (limités à 160 caractères) : le Short Message Service (SMS). Ce
nouveau service a donné naissance au langage SMS faisant de très nombreux adeptes, notam-
ment chez les jeunes générations, dû au fait de minimiser le coût des envois. Néanmoins, il a été
constaté que ce langage engendre des problèmes de communication avec les autres générations,
moins jeunes, qui sont ainsi “info-exclues”. D’autre part, deux applications1 existent déjà mais
elles ne sont pas multilingues et leur dictionnaire reste limité rendant difficile la lisibilité des
messages traduits.
1. www.langagesms.com & www.traducteur-sms.com
1
2 Introduction
1.2 Objectifs
Ainsi, ce projet a pour objectifs d’implémenter deux techniques amplement connues pour la
traduction :
1. traduction basée sur les règles [10]
2. traduction statistiques [8]
pour un traducteur du langage SMS au langage naturel pour trois langues différentes (chinois,
anglais et français). La première version devra être basée sur une méthode de calcul prenant en
compte des règles (Rule-Based Machine Translation) et sera appliquée sur les corpora de textes en
anglais et en chinois à cause de leur taille minimale. La deuxième version du traducteur sera
basée sur une méthode statistique (Statisitical Machine Translation) qui concernera uniquement
la langue française grâce à un corpus de plus grande taille. Enfin, un service Web sera implanté
afin de proposer ces services de traduction aux utilisateurs via Internet ou par le biais d’une
application pour smartphones.
1.3 Contraintes
Ce projet devra être réalisé sur une période de 6 mois (débutant en Octobre 2011 et se finissant
en Mars 2012) et avec le langage de programmation Java. Les deux méthodes citées plus haut
(basées sur les règles et sur les statistiques) devront être impérativement utilisées et implantées
dans des prototypes distincts. De plus, les logiciels Anymalign et MOSES [7] devront être uti-
lisés pour le modèle statistique. Enfin, les traducteurs devront prendre en compte le chinois,
l’anglais et le français.
1.4 Plan
Tout d’abord nous détaillerons ce qu’est le langage SMS, les différents principes de la tra-
duction automatique ainsi que ce qui a été réalisé concernant la traduction du langage SMS au
langage naturel. Ensuite, nous préciserons les étapes du projet qui ont déjà été réalisées ou qui
sont en cours. Enfin, nous aborderons la plannification du projet.Chapitre 2
Etat de l’art
2.1 Caractéristiques Linguistiques du Langage SMS
Le SMS (Short Message Service) est un service d’échange de messages écrits limités à 160
caractères. Cette limitation a engendré l’apparition du langage SMS qui est une nouvelle forme
de communication écrite pour les nouvelles technologies de communication. Ce langage est
caractérisé par des écarts importants et systématiques des normes orthographiques. De plus,
s’ajoute à celui-ci une utilisation non conventionnelle des symboles alphabétiques et de la
ponctuation pour à la fois introduire du contenu phonétique et du méta-dialogue comme les
émotions. Ces modifications du langage naturel permettent de réduire la longueur du message
dans le but de ne pas dépasser cette limitation de taille pour ne pas engendrer de surcoût ou
encore pour accélérer la saisie de celui-ci. Les utilisateurs vont donc privilégier d’avantage le
sens du message en écrivant rapidement, notamment avec peu de mots et peu de caractères
mais en gardant une certaine idée de la syntaxe.
Les particularités de ce langage sont sa perpétuelle évolution et sa multitude de variations
possibles. La seule limite aux variations des SMS est l’imagination des utilisateurs. Ainsi, la
composition des mots est totalement imprévisible. De plus, certains mots peuvent apparaître
seulement occasionnellement (lors d’un événement sportif par exemple). Il est donc très diffi-
cile de normaliser ce langage. Néanmoins, on constate un certain nombre de procédés qui le
caractérise permettant de raccourcir les phrases et les mots comme le démontrent Bove [3] et
Wikipedia2 . Le langage SMS est un langage particulièrement phonétique qui tend à rendre le
même son mais avec une réalisation lexicale simplifiée.
2. http ://fr.wikipedia.org/ (Article Langage SMS et Article Emoticônes)
34 Etat de l’art
2.1.1 L’Abréviation
Le principe de l’abréviation est de supprimer la plupart des voyelles ainsi que certaines
consonnes tout en conservant un mot plus ou moins lisible et compréhensible. Cela s’explique
par le fait que les consonnes ont une valeur informative plus forte que les voyelles. Ce procédé
permet de réduire considérablement la taille d’un mot. On obtient donc une succession de
consonnes principales du mot. (Voir le tableau 2.1)
slt = salut
prtt = pourtant
tjs, tjr, tjrs = toujours
lgtps = longtemps
Table 2.1 – Exemples d’abréviations
2.1.2 Le Rébus typographique
Le rébus typographique est le procédé par lequel certaines séquences de lettres, d’un mot ou
d’une suite de mots, sont remplacées par un arrangement de chiffres et/ou de lettres correspon-
dant au même phonème que la séquence concernée. Ce procédé est basé essentiellement sur la
phonétique. On utilise la valeur épellative des lettres, des chiffres et des caractères pour obtenir
le mot. (Voir le tableau 2.2)
G = j’ai a12c4 = à un de ces quatre
C = c’est, ces koi 2 9 = quoi de neuf
2m1 = demain mr6 = merci
bi1 = bien graV = gravé
gt = j’étais grav = grave
jamé = jamais
Table 2.2 – Exemples de rébus typographiques2.1 Caractéristiques Linguistiques du Langage SMS 5
2.1.3 La Contraction
La contraction correspond à la formation d’un mot par la réunion de deux ou plusieurs unités
lexicales comme illustré dans le tableau 6.4.
Exemples de patrons Exemples
j + pronom jte (= je te)
« JE »
j + verbe jsui (= je suis)
k + article défini kle (= que le)
« QUE » k + pronom démonstratif kce (= que ce)
k + pronom personnel ktu (= que tu)
s + pronom ske (= ce que)
« CE / SE »
s + verbe svoir (= se voir)
m + pronom mle (= me le)
« ME »
m + verbe mparl (= me parle)
Table 2.3 – Exemples de contractions
2.1.4 Les Émotions
Les émotions caractérisées par des émoticônes sont plus souvent utilisées dans le langage
d’Internet car elles nécessitent des caractères autres que des chiffres et des lettres qui sont plus
difficiles d’accès. Cependant, ceux-ci sont de plus en plus utilisés car ils sont limités en caractères
ce qui permet d’exprimer facilement des émotions. Les émotions sont représentées via certaines
représentations du corps humain avec des caractères spécifiques comme le démontre le tableau
2.4.
Signification Emoticônes Signification Emoticônes
Sourire :-) ^^^_^ Triste, déçu :-( :(
Riant de toutes ses dents :-D xD XD Clin d’oeil ;-)
Tirant la langue :-P Etonné, bouche bée, Oh ! :-o :-O
Pleurant :’( Indifférence :-|
Table 2.4 – Exemples d’émoticônes
Ce procédé est hors de notre étude car il n’intervient pas dans la traduction puisque ceux-ci
restent identiques dans les deux cas.6 Etat de l’art
2.1.5 La Combinaison de Procédés
Les procédés énoncés précédemment peuvent être combinés les uns avec les autres pour
augmenter la contraction d’un mot ou d’une phrase. Par exemple, adm1 = à demain. Ainsi on a
un rébus pour le mot "demain" (dm1) et la contraction entre deux mots (a et dm1).
2.2 Les Différents Modèles de Traduction Automatique
Selon Dorr [4], différents modèles de traduction ont été réalisés afin de pouvoir traduire au
mieux des ensembles de textes. Ces modèles se déclinent en deux catégories : les modèles lin-
guistiques et les modèles statistiques.
2.2.1 Les Paradigmes Basés sur la Linguistique
Il s’agit de l’ensemble des systèmes qui prennent en compte des informations autres que le
seul lexique, par exemple la syntaxe ou la sémantique des phrases pour produire un résultat
dans le langage cible.
Modèle Basé sur le Lexique (Lexical-based MT)
Les systèmes de traduction basés sur ce modèle font appel à des règles particulières qui réa-
lisent la correspondance entre une entrée lexicale d’un mot dans un langage vers une entrée du
même mot mais dans un autre langage. Plusieurs implémentations du système ont été faites, et
l’une d’elle se ramène à un problème de transfert de mot. Ce type d’approche fait appel à des
structures de données particulières (des arbres). Les relations entre un mot dans un langage et sa
traduction dans un autre sont construites à partir d’un lexique bilingue. Ce lexique associe deux
arbres de départ et d’arrivée à travers des relations entre chaque mot. De cette façon, chaque
entrée du lexique contient une relation entre une phrase dans le langage source et une phrase
dans le langage voulu. Un des incovénients de cette approche est qu’elle nécessite d’utiliser
des arbres complets qui doivent être stockés en mémoire pour chaque combinaison de langage
(langage source/langage cible), ceci peut s’avérer être très lourd.
Modèle Basé sur les Règles (Rule-based MT)
Ce type de modèle est associé aux systèmes qui prennent en compte différents niveaux de
règles linguistiques de traduction entre deux langages. Il est basé sur des lexiques mais aussi sur
un système de règles. On trouve deux principaux types de règles : les "M-Règles" ("meaning-2.2 Les Différents Modèles de Traduction Automatique 7
preserving rules") qui prennent en compte le sens du mot, et les "S-Règles" ("non-meaningful
rules") qui traitent d’avantage la syntaxe. Les "M-Règles" font d’avantage appel aux lexiques
pour déduire la signification du mot. Cette approche diffère de celle basée sur le lexique, car
les exigences particulières de chaque mot (ou entrée lexicale) sont implémentées dans un méca-
nisme de contrôle plutôt que dans le lexique lui-même. On retrouve couramment certains types
de règles [2]. Par exemple, il existe des règles de formation qui traitent la formation des mots
composés et qui servent à mettre en correspondance les structures ainsi établies. Des règles
syntagmatiques et des règles de correspondance définissent des critères linguistiques comme
c’est le cas avec les traducteurs en ligne comme Reverso ou Systran. Les règles syntagmatiques
font appel à des règles de réécriture qui servent à décomposer des phrases. Les règles de cor-
respondances sont employées pour faire correspondre les règles précédentes entre les langages
source et cible. Le modèle basé sur les règles peut devenir complexe car il nécessite d’avoir des
dictionnaires bilingues conséquents avec des informations linguistiques bien précises [9]. Un
autre inconvénient de cette approche est que la structure de la phrase (avec l’organisation des
mots à l’intérieur) dépend du langage ce qui peut faire que certaines règles ne peuvent pas être
applicables.
Modèle Basé sur les Transferts (Transfer-based MT)
Le but général de ce type de structure est de générer un texte syntaxiquement correct dans
un langage précis. Ceci se fait en transformant une représentation dans le langage source en
une autre représentation dans le langage cible. Les règles de transfert qui permettent cette
conversion dépendent en partie des langages manipulés. Il y a deux principaux types de trans-
fert 3 : les transferts lexicaux et les transferts structurels. Les premiers servent à affecter pour
chaque mot une traduction appropriée selon le contexte de la phrase où il est. Les seconds
permettent d’assurer le bon ordonnancement des mots dans la phrase et entreprennent d’autres
adaptations structurelles (comme des transpositions de mots). Néanmoins, certaines de ces
règles doivent être ajustées afin de ne pas faire de confusion, en particulier quand les langages
concernés sont syntaxiquement proches d’autres langages. Ce système requiert également des
règles de liaisons qui permettent de faire une correspondance entre un texte avec son langage
et différentes représentations internes. Cependant, ce système possède un inconvénient : les
différentes représentations faites à partir de l’analyse des langages utilisés dépendent très forte-
ment des langages eux-mêmes, ce qui implique de tout reconstruire pour chaque langage utilisé.
Modèle Basé sur les Inter-langues (Interlingua-based MT)
Le but de ces architectures est de trouver une représentation sémantique commune entre des
textes dans des langages différents. Le principe est que l’analyse d’un texte dans un langage
source devrait aboutir à une représentation du texte qui doit être indépendante de tout langage.
3. http ://www.linguatec.fr/products/tr/information/technology/mtranslation8 Etat de l’art
Ainsi, le texte dans le langage cible est généré à partir d’un langage "neutre" qui est celui de
la représentation du texte. On passe ainsi par une représentation intermédiaire, qui n’est pas
dans les langages concernés (inter-langue). Ainsi, l’aspect sémantique des textes a d’avantage
d’importance et sert à passer d’une représentation à une autre. Ce genre d’achitecture comporte
un inconvénient : comme aucun aspect syntaxique n’est pris en compte, le style original du texte
est perdu, et le texte traduit est d’avantage paraphrasé.
2.2.2 Les Paradigmes Basés sur les Statistiques
Généralement, ces approches doivent se baser sur de très gros corpora, ce qui n’est pas le
cas de la majorité de nos corpora, excepté pour le français même si celui-ci contient que 40000
phrases SMS traduites.
Modèle Basé sur les Statistiques (Statistical-based MT)
Cette approche dépend fortement de l’analyse statistique des corpora parallèles bilingues. Le
modèle utilise deux modèles particuliers : un modèle de traduction et un modèle de la langue. Le
modèle de traduction met en évidence la probabilité qu’un mot SMS ait la meilleure traduction
d’un mot en langue naturelle.
p(sms|txt) (2.1)
Le modèle de la langue détermine la probabilité que le texte concerné soit le plus cohérent
possible et qu’il propose la meilleure traduction possible.
p(txt) (2.2)
Ainsi, le produit de ces probabilités
p(sms|txt).p(txt) (2.3)
permet de déterminer la meilleure traduction possible. L’inconvénient de cette méthode est
qu’elle nécessite des gros corpora afin d’avoir des probabilités plus précises.
Modèle Basé sur les Exemples (Example-based MT)
Ce paradigme de traduction est basé sur une émulation de la traduction humaine en recon-
naissant les similitudes entre une phrase dans un langage source et différents éléments qui ont
déjà été traduits dans le passé. Il s’agit finalement d’une traduction par analogie. Cela fait appel
à une base de données qui contient des traductions parallèles qui permettent de trouver des
phrases ou des mots qui ressemblent le plus à ce que l’on cherche. Les différentes traductions2.3 La Traduction du Langage SMS au Langage Naturel 9 trouvées sont par la suite combinées et traitées pour former une nouvelle phrase traduite. Pour déterminer si un mot peut correspondre à un autre, un "écart sémantique" est évalué entre eux. Cet écart permet de définir si les deux mots sont très proches en ce qui concerne leur sens. Cet écart est évalué avec un principes d’ontologies (représentations conceptuelles des mots) ou avec un thésaurus (liste organisée de termes en rapport avec un mot défini). La précision et la qualité de la traduction dépendent très fortement de la taille de la base de données utilisée. De plus, la structure de la phrase à traiter doit être sensiblement la même que celles présentes dans la base de données, sinon il risque d’y avoir des traductions incohérentes. 2.3 La Traduction du Langage SMS au Langage Naturel Afin de pouvoir réaliser notre projet de traduction de SMS, une large étude de l’existant a été réalisée afin d’avoir connaissance des recherches qui ont déjà été menées à ce sujet ainsi que leurs enjeux. Les recherches les plus interessantes pour notre projet ont été résumées ci dessous. Une première équipe de recherche Belge [5] a mis en place une opération de collecte de SMS permettant d’obtenir 30 000 SMS en langue française. Ils ont par la suite réalisé le formatage et la traduction de ces SMS en langage naturel. Leurs recherches ont mis en évidence diffé- rents problèmes comme le fait que les utilisateurs adoptent rapidement de nouvelles habitudes d’écriture. Ces utilisateurs privilégient d’avantage le sens du message en utilisant peu de mots et de caractères ce qui rend la composition des SMS imprévisible. Ils ont put également mettre en évidence que le langage SMS est un mélange de codes et d’expressions empruntés à d’autres formes de dialogue. Par ailleurs, une équipe Française de recherche d’Orange à Lannion [6] s’est penchée sur le problème de la normalisation des SMS. Leur étude a mis en évidence le fait que les messages SMS sont caractérisés par des écarts importants et systématiques des normes orthographiques. Les symboles alphabétiques, la ponctuation et des contenus phonétiques sont également utilisés intensivement, notamment pour exprimer des émotions. Différentes approches ont été réalisées pour la normalisation des SMS. Le problème peut par exemple être ramené à un problème de correction d’orthographe. La correction est alors basée sur du mot à mot tout en prenant en compte leur contexte. Une autre façon de faire est de considérer le langage SMS comme un langage étranger ce qui ramène la normalisation à une traduction simple. Ainsi, plusieurs mots traduits peuvent correspondre à un mot en SMS. Différents modèles comme des modèles statistiques peuvent se charger de rendre cohérent l’ordre des mots traduits. Les chercheurs ont également fait appel à un modèle qui se base d’avantage sur la prononciation. Cette ap-
10 Etat de l’art
proche part du principe que l’orthographe du SMS se rapproche fortement de la prononciation
du mot. Le SMS est alors vu comme une approximation syllabique de la forme phonétique.
Ceci leur a permis d’effectuer certains types de corrections. Afin de faire correspondre chaque
mot SMS à sa traduction et d’optimiser les résultats, les logiciels GIZA++ et Moses ont été utilisés.
Enfin, une équipe Chinoise [11] a mis en évidence l’ambiguité des mots SMS en analyant les
forums de discussions (chats) chinois sur Internet. Du fait des nombreuses ressemblances entre
les messages SMS et ceux envoyés sur les chats, les résultats de leur étude peuvent être facile-
ment transposés au langage SMS. De part son étude, l’équipe a put déduire que la plupart des
mots de ce langage ne sont pas inclus dans le dictionnaire car le langage SMS est très dynamique
et change continuellement. De plus, il peut y avoir plusieurs significations pour un mot SMS.
L’étude a permis de mettre en évidence que la plupart des mots des chats et donc des SMS sont
crées à partir de leur prononciation et non pas de leur orthographe.
2.4 Les Applications Existantes
Nous avons pu repérer et tester deux traducteurs SMS disponibles sur Internet. Le premier
d’entre eux est présent sur www.langagesms.com. Le deuxième est accessible sur certains ré-
seaux sociaux, sur Internet et sur Android via le site www.traducteur-sms.com. Néanmoins,
ces traducteurs en ligne sont assez limités. Le premier possède un dictionnaire de seulement
369 mots, ce qui est assez restreint pour proposer une bonne traduction. Celle-ci se rapproche
essentiellement d’une traduction mot à mot lorsqu’elle est efficace. En effet, nous avons essayé
de traduire un SMS simple provenant de notre corpus français ("keskon peu envoyé com sms"),
mais le résultat produit par l’application fut totalement inefficace : celle-ci produisit en traduc-
tion "keskon peu envoyé com sms". La deuxième application fut bien plus performante. Celle-ci
dispose d’un dictionnaire de 9961 mots en mémoire et ses traductions sont biens précises. Effec-
tivement, nous avons utilisé le même exemple que précédement et l’application nous retourna
en version traduite "Qu’est-ce qu’on peut envoyé comme SMS". Le seul mot erroné ("envoyé")
n’était simplement pas présent dans le dictionnaire utilisé. Néanmoins, cette application est
robuste car elle prend en compte les mots composés et de nombreuses caractéristiques propres
au langage SMS (abréviations et phonétique notamment).Chapitre 3
Normalisation du Corpus
Nous avons en notre possession quatre corpora (deux en français, un en anglais et un en
chinois). Les corpora français proviennent de l’Université Catholique de Louvain [5] et de la
société Orange Labs de Lannion [6]. Le corpus anglais provient quant à lui de l’Institut pour
la Recherche sur l’Infocommunication de Singapour [12] et le corpus chinois de l’Université de
Tsinghua à Pekin [11]. Ceux-ci sont dans des formats différents. Certains sont dans un fichier
texte, d’autres dans un fichier Excel avec une hiérarchisation des données différentes. Il a donc
fallut les normaliser pour obtenir des formats identiques et traitables de la même façon. Notre
choix s’est porté sur le métalangage XML.
3.1 Le Métalangage XML et la Validation avec une DTD
3.1.1 Qu’est ce que le XML ?
Le XML (eXtensible Markup Language) est une spécification proposée par le W3C (World Wide
Web Consortium) en 1998. C’est un métalangage standardisé ouvert, à la grammaire stricte, nor-
malisé et structuré dans un fichier texte. Il permet aussi de hiérarchiser et de parcourir des
données rapidement. Elles sont encapsulées dans des balises qui peuvent être définies par l’uti-
lisateur.
Les Règles
Le XML respecte un certain nombre de règles telles que :
1. Le respect de la casse,
2. La fermeture de chaque balise ouverte,
3. L’encadrement par des guillemets des valeurs d’attributs,
1112 Normalisation du Corpus
4. Les balises ne peuvent être entrelacées.
Les Avantages et Inconvénients
Le XML a pour avantages de pouvoir être utilisable pour n’importe quel jeu de caractères
ce qui est intéressant pour notre projet car nous traitons différentes langues (chinois, anglais et
français). Il permet aussi de structurer l’information sous une forme plus robuste que d’autres
fichiers (binaires, . . . ). De plus, le parcours des données s’effectue de manière rapide et efficace
ce qui va nous être très utile pour la création du dictionnaire à partir de ces corpora qui sont
de taille plus ou moins importante. Cependant, les données stockées au format texte sont plus
volumineuses qu’au format binaire.
3.1.2 La DTD
Un document XML est dit "valide" s’il est "bien formé" et qu’il possède une DTD
(Document Type Definition).
La DTD permet de définir la structure que l’on veut donner à notre document XML (Voir le
tableau 3.1). Dans celui-ci, on définit les balises pouvant être utilisées dans le document XML
avec des attributs si nécessaire ainsi que la hiérarchisation entre les balises.
< !ELEMENT chat (sms,txt)>
< !ATTLIST chat id ID #REQUIRED>
< !ELEMENT sms>
< !ELEMENT txt>
Table 3.1 – DTD pour la validation des corpora
3.2 Les Corpora formatés en XML
Ces corpora ont été construits avec plusieurs scripts AWK.
Le français
keskon peu envoyé com sms
Qu’est-ce qu’on peut envoyer comme SMS
Table 3.2 – Extrait du corpus français formaté3.2 Les Corpora formatés en XML 13
Le chinois
JJ,你LG坐车了米有啊
姐姐,你老公坐车了没有啊
Table 3.3 – Extrait du corpus chinois formaté
L’anglais
Who r u talking 2 ?
Who are you talking to ?
Table 3.4 – Extrait du corpus anglais formaté14 Normalisation du Corpus
Chapitre 4
Traduction Basée sur des Règles
La traduction basée sur un système de règles est l’un des deux types de traduction étudiés au
cours de ce projet. Elle concerne essentiellement les petits corpora (en anglais et en chinois) car
ceux-ci peuvent générer d’avantage de résultats. L’intérêt principal de cette méthode est qu’un
dictionnaire regroupant des paires de mots SMS et de mots en langage naturel est établi.
4.1 Création du Dictionnaire
4.1.1 La méthode de Smadja (1996)
Afin de pouvoir établir le dictionnaire, des recherches ont été réalisées concernant une mé-
thode particulière [10]). Cette méthode utilise un modèle basé sur un système de règles qui vont
servir à remplir le dictionnaire. Cette méthode est représentée par le schéma 4.1.
Figure 4.1 – Schéma de la méthode de Smadja
1516 Traduction Basée sur des Règles
La méthode possède deux phases qui traitent un corpus parallèle. La première phase calcule
un Dice pour chaque mot de la phrase SMS avec tous les mots de la phrase en langue natu-
relle qui correspond. Par exemple, pour la phrase SMS "cc cv b1" et sa version texte "Coucou
ça va bien", on obtient pour le mot "cc", les Dice : Dice(cc,Coucou), Dice(cc,ça), Dice(cc,va),
Dice(cc,bien). La deuxième phase applique les règles que l’on souhaite appliquer aux différents
Dice obtenus ce qui nous permet de conserver le Dice avec la combinaison
la plus probable. Ce Dice pourra être stocké dans une base de données qui correspond au dic-
tionnaire que l’on souhaite obtenir.
4.1.2 Le Dice
Le Dice est un coefficient utilisé par ce modèle et qui se base sur un mot écrit en langage SMS
et un mot écrit en langage naturel. Il calcule dans un premier temps la fréquence du couple
, c’est-à-dire le nombre de fois où l’on retrouve ces deux mots ensemble
dans une paire de texte .
f (msms , mtxt ) (4.1)
Par la suite, les fréquences du mot en SMS et du mot en langage naturel sont calculées, respec-
tivement
f (msms ) (4.2)
et
f (mtxt ) (4.3)
La formule ci-dessous permet alors de déterminer le coefficient Dice.
2 ∗ f (msms , mtxt )
Dice(X, Y) = (4.4)
f (msms ) + f (mtxt )
Ceci permettra alors de déterminer quel couple de mots est le plus
probable suivant le coefficient Dice et donc quel mot en langage naturel est la meilleure traduc-
tion du mot SMS.4.1 Création du Dictionnaire 17
4.1.3 Des calculs suplémentaires
Par ailleurs, des calculs supplémentaires ont été réalisés. Ces calculs permettent de voir si le
Dice peut être remplacé par un autre coefficient afin d’établir un meilleur dictionnaire.
Pointwise Mutual Information (PMI)
f (X, Y)
PMI(X, Y) = log (4.5)
f (X) ∗ f (Y)
Mutual expectation (ME)
2 ∗ f 2 (X, Y)
ME(X, Y) = (4.6)
f (X) + f (Y)
Jaccard
f (X, Y)
Jaccard(X, Y) = (4.7)
f (X, Y) + ( f (X) − f (X, Y)) + ( f (Y) − f (X, Y))
Log Likelihood ratio (LogLike)
LogLike(X, Y) = 2∗(log θs1
1 (1 − θ1 )
n1−s1
+log θs2
2 (1 − θ2 )
n2−s2
−log θs1 (1 − θ)n1−s1 −log θs2 (1 − θ)n2−s2 )
(4.8)
avec N = Nombre de couples formés X,Y où X est un mot SMS et Y un mot en langue naturel
et
s1 = f (X, Y) s2 = f (Y) − f (X, Y)
n1 = f (X) n2 = N − f (X)
f (Y) f (Y)
θ= N θs1 = ( N )s1
θ1 = n1
s1
θ2 = n2
s2
Table 4.1 – Détail du LogLike18 Traduction Basée sur des Règles
4.2 Évaluation du Dictionnaire
Afin de voir si le dictionnaire réalisé propose des traductions acceptables des mots SMS, des
évaluations ont été réalisées. Ces évaluations se basent sur le calcul d’un coefficient nommé
Précision. Plusieurs types de précisions allant de 1 à 5 (Précision à 1, Précision à 2, . . . , Précision
à 5) ont été déterminés. La Précision utilise une liste de mots (ici en langage naturel) qui sont
tous des traductions possibles d’un mot SMS, c’est à dire les mots pour lesquels un Dice (ou un
autre coefficient) a été calculé. Cette liste de mots est ordonnée en fonction du coefficient visé
de telle sorte à ce que le mot en tête de liste soit la meilleure traduction. A l’inverse, le mot en
queue de liste sera la pire traduction possible. Ainsi, pour le cas du Dice, les mots qui ont le Dice
le plus élévé seront en tête de liste, il en est de même pour les autres coefficients. La Précision
permet de déterminer si, pour un mot en langage SMS donné, la meilleure traduction se trouve
parmi les premiers mots en langage naturel proposé. Par exemple, la Précision à 1 détermine si
la meilleure traduction d’un mot SMS est le 1er mot proposé. Également, la Précision à 2 déter-
mine si la meilleure traduction d’un mot est dans les 2 premiers mots de la listes et ainsi de suite.
Nombre de fois que le premier mot de la liste est la meilleure traduction
Precision à 1 =
Le nombre de mot qui ont été traduit (=échantillon)
Ainsi, plusieurs évaluations ont été réalisées permettant d’évaluer la qualité des traductions
avec les différents coefficients utilisés (Dice, Jaccard, ME, PMI et LogLike).
Précision Dice PMI ME Jaccard LogLike
@1 0.662 0.372 0.727 0.636 0.719
@2 0.797 0.511 0.835 0.771 0.805
Anglais @3 0.853 0.615 0.879 0.818 0.866
@4 0.870 0.675 0.900 0.853 0.879
@5 0.887 0.693 0.905 0.857 0.883
@1 0.912
@2 0.930
Chinois @3 0.947
@4 0.947
@5 0.947
Table 4.2 – Résultat des évaluations pour l’Anglais et le Chinois
En analysant les résultats des évaluations faites, on peut constater la chose suivante. Pour
les calculs des Précisions, plus les résultats obtenus sont proches de 1.00, meilleures sont les
traductions. Ainsi, on peut constater que le PMI est le coefficient le moins adapté à notre système
de traduction. En effet, parmi les 5 calculs réalisés, aucun n’a une valeur qui atteint 0.7, d’autant4.3 Règles de Traduction 19
plus que la seule Précision qui s’en rapproche est la Précision à 5. Néanmoins, bien que le Dice
fut le coefficient utilisé par le système de traduction, celui-ci n’est pas le meilleur. En effet, si on
le compare au LogLike, presque toutes ses Précisions, mis à part la Précision à 5, sont inférieures
à celles du LogLike. Ce dernier serait alors d’avantage intéressant. Or, on peut remarquer que
le ME est lui même supérieur au LogLike car les valeurs obtenues par les 5 Précisions calculées
sont toutes supérieures. On peut conclure de cette évaluation que le coefficient Dice peut être
remplacé par un coefficient offrant de meilleurs résultats (ME), bien qu’il possède des Précisions
honorables. Le Dice peut ainsi être remplacé aisément dans le système de traduction grâce aux
principes de génie logiciel appliqués durant l’élaboration des différents programmes.
Concernant les évaluations de la traduction chinoise, on peut constater que seul la Dice a été
calculé. Les autres coefficients n’ont pas été déterminés pour deux raisons. Tout d‘abord, un
manque de temps est apparu empêchant de pouvoir réaliser toutes les évaluations. Néanmoins,
celle-ci peuvent être réalisées ultérieurement via le programme prévu à cet effet. La deuxième
raison est que les résultats pouvant être obtenus avec ces évaluations risquent d’être erronés.
En effet, la langue chinoise ne repose pas sur les mêmes principes que les langues occidentales
comme le français. Comme un symbole peut designer un mot ou une partie de mot, il est difficile
de pouvoir déterminer quelle est la bonne traduction du symbole considéré. Ce problème s’ac-
centue d’autant plus que, comme les membres du groupe n’ont pas de compétences en chinois,
les symboles choisis risquent d’être incorrects.
4.3 Règles de Traduction
La méthode de Smadja utilisée pour effectuer la traduction mot à mot utilise également un
ensemble de règles qui s’appliquent sur les résultats obtenus avec les différents coefficients
déterminés (notamment le Dice). Ainsi, pour obtenir un dictionnaire efficace avec la meilleure
traduction possible pour chaque mot, plusieurs règles seront appliquées sur chaque Dice calculé.
1. Conserver les coefficients qui ont la fréquence du couple (mot SMS/mot clair) supérieure
à 5. Cela va permettre de donner plus de force aux éléments fréquents.
2. Pour chaque mot SMS, on conservera que le Dice le plus élevé. Si on a deux Dice avec la
même valeur, ils seront tout les deux pris en compte.20 Traduction Basée sur des Règles
Chapitre 5
Traduction Basée sur des Modèles
Statistiques
Le second type de traduction utilisé ici est une traduction basée sur des modèles statistiques.
Ces modèles probabilistes sont plus élaborés et plus complexes d’utilisation et de mise en
oeuvre. Cependant ils offrent des traductions plus efficaces qui prennent en compte notamment
les formes conjuguées et les expressions courantes. Les corpora de taille conséquente sont les
plus intéressants ici car ils contiennent assez de données pour pouvoir établir de bons modèles.
Ainsi, les corpus regroupant les messages en français est utilisé. Deux outils ici ont été utilisés,
à savoir Anymalign et Moses.
5.1 Anymalign
Anymalign est un outil crée par A. Lardilleux afin d’établir un modèle de traduction. Ce mo-
dèle permet d’établir un ensemble de probabilités indiquant qu’un mot SMS a plus de chance
d’être traduit par un mot en langage naturel plutôt qu’un autre. Ce programme se base sur
deux corpora de textes qui contiennent tous les textes en langage SMS pour l’un et tous les
textes en langage naturel pour l’autre. Ces corpora ont été produits à partir du corpus au format
XML utilisé et sont parallèles et alignés. Ils sont parallèles car pour une ligne avec un langage
et un fichier donné, on trouve à la même position dans l’autre fichier la ligne équivalente dans
l’autre langue. Ils sont également alignés car les mots gardent leur position dans les textes et,
pour un mot dans un texte d’un fichier, on trouve sa traduction à la même position dans l’autre
fichier. Initialement, un autre programme aurait du être utilisé pour produire ce modèle de
traduction : il s’agissait de Giza++. Néanmoins, ce fut Anymalign qui fut choisi. Ce choix se
justifie par le fait qu’Anymalign est un programme qui produit rapidement des résultats et qui
les améliore en fonction de sa durée d’exécution. Ainsi, on exécutant le programme plusieurs
2122 Traduction Basée sur des Modèles Statistiques heures à la suite, les résultats produits seront plus intéressants que ceux de Giza++. De plus, son utilisation est nettement plus aisée que Giza++ pour des étudiants ayant peu de connais- sances dans le domaine de la traduction, car elle ne fait pas appel à des notions et des termes complexes contrairement à Giza++. L’inconvénient majeur d’Anymalign est que son exécution est nettement plus lente que Giza++, cette différence de temps de calculs étant expliquée par les langages dans lesquels les programmes ont été développés (Python pour Anymalign et C/C++ pour Giza++). 5.2 Moses Moses, quant à lui, est utilisé pour produire un modèle de la langue mais également pour l’utiliser avec le modèle de traduction pour pouvoir traduire un texte. Ce modèle de la langue sert à déterminer les caractéristiques de la langue afin de pouvoir produire une traduction la plus proche de la langue naturelle possible. Ainsi, les formes conjuguées (comme les participes passés en français) et les expressions populaires sont d’avantage utilisées par ce modèle rendant ainsi la traduction plus réaliste. Pour que Moses puisse gérer les textes à traduire et traduits, deux fichiers doivent être créés. Le texte à traduire devra être enregistré dans un de ces fichiers et sa traduction sera mise, par le programme, dans l’autre.
Chapitre 6
Développement
Afin de pouvoir établir le système de traduction de textes en langage SMS en textes en langage
naturel, différentes technologies et différents outils ont été utilisés.
6.1 Traitement des données reçues
Une des premières étapes du projet était de pouvoir récolter un grand nombre de corpora
contenant des textes en langage SMS et des textes en langage naturel. Divers organismes5 ont
été contactés, et ceux-ci ont put fournir leurs données. Néanmoins, ces données ont été envoyées
sous différentes formes, que ce soit au format texte (.txt) ou au format tableur (.xsl, .ods, .sxc
et .csv). Ainsi, il a fallu créer pour chaque type de fichier envoyé un script AWK permettant
de le traiter et de produire un fichier au format XML avec toutes les données intéressantes. Le
langage AWK est un langage de traitement des fichiers très puissant qui permet à la fois de
traiter très rapidement un fichier et de le manipuler facilement. C’est pourquoi il a été choisi
pour traiter les fichiers reçus.
6.2 Analyse de Système
Un langage pour 4 programmes
Pour pouvoir mettre en place le système de traduction et le tester, différents programmes
(au nombre de 4) ont été réalisés. Ces programmes ont tous les quatre été implémentés avec le
même langage qui est Java. Il s’agit d’un langage portable car le fichier exécutable produit peut
être utilisé sur n’importe quelle machine sans nécessiter de recompilation. Java est également
5. L’Université Catholique de Louvain [5], la société Orange Labs de Lannion [6], l’Institut pour la Recherche
sur l’Infocommunication de Singapour [12] & l’Université de Tsinghua à Pekin [11].
2324 Développement
un langage multiplateforme, c’est-à-dire qu’il peut s’exécuter aussi bien sous Linux, Mac OSx et
Windows. Ainsi, les programmes ont pu être développés plus facilement et peuvent être utilisés
sous n’importe quelle machine de l’université. De plus, grâce à son paradigme Orienté Objet,
les programmes réalisés sont d’avantage modulaires et maintenables.
Par ailleurs, un EDI6 a été utilisé : il s’agit d’Eclipse7 . Il s’agit d’un logiciel permettant de dé-
velopper les différents programmes tout en proposant à la fois des fonctionnalités très utiles
comme la réalisation de tests unitaires (faits avec JUnit8 ), la génération de documentation au
format HTML et également la gestion des dépôts (comme Subversion9 ).
Le programme DictionnaireSMS
Le premier programme (DictionnaireSMS) a été établi dans le but de traiter les corpora au
format XML pour pouvoir remplir une base de données. C’est ce programme qui est chargé
d’effectuer les différents calculs comme le Dice. Différents packages ont été construits et, avec
toute la puissance du paradigme Orienté Objet de Java, ont permis d’avoir une application faci-
lement maintenable et reprenable. Différentes librairies externes ont été utilisées que ce soit pour
pouvoir manipuler la base de données (JDBC) et traiter les fichiers XML (JDOM). Néanmoins,
l’API Java de base n’était pas suffisante pour pouvoir effectuer tous les traitements. En effet, il
a fallut utilisant une librairie externe proposée par Apache pour pouvoir utiliser des structures
de données optimisées et efficaces pour les traitements à réaliser (commons-collections). Ainsi,
des MultikeyMap ont put être utilisées pour pouvoir par exemple stocker en une seule fois un
Dice avec les deux mots utilisés et leur fréquence d’apparition.
Grâce à la documentation integrée dans le code (sous format Javadoc) et à la modélisation du
programme, DictionnaireSMS est facilement reprenable. En effet, s’il est nécessaire de traiter
un nouveau corpus au format XML, il suffira de le référencer dans une classe prévue à cet
effet (Corpora.java). De même, si de nouveaux calculs doivent être réalisés, les développeurs
n’auront qu’à établir des classes Java héritant de celles existantes comme AutresCalculsBuilder
par exemple. Également différents types de langues peuvent être traités par ce programme. En
effet, dans certaines langues (comme l’anglais ou le français) les mots sont séparés dans les
phrases par la ponctuation et par des espaces entre eux. Or, ce n’est pas le cas dans d’autres
langues. Par exemple pour le chinois, les mots sont collés les uns aux autres, sans espace, et la
ponctuation a une importance très faible. Ainsi, les langues ayant un type plutôt occidental sont
gérées par une classe particulière (EnglishDiceBuilder), et celles qui se rapprochent du chinois
sont gérées par ChineseDiceBuilder. Enfin, afin de préserver les mots des différentes langues
possibles, l’encodage UTF8 a été choisi. Il s’agit d’un encodage qui prend un compte un nombre
6. Environnement de Développement Intégré
7. http ://www.eclipse.org/
8. http ://www.junit.org/
9. http ://subversion.apache.org/6.2 Analyse de Système 25
très grand de symboles protégeant ainsi les mots avec des caractères non latins comme le chinois.
Figure 6.1 – Morceau du diagramme de classe du programme DictionnaireSMSVous pouvez aussi lire

















































