BASES DE DONNÉES AVANCÉES - DATAWAREHOUSE ET NOSQL INTRODUCTION THIERRY HAMON - LIMSI
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Bases de Données Avancées
DataWareHouse et NoSQL
Introduction
Thierry Hamon
Bureau H202
Institut Galil�e - Universit� Paris 13
&
LIMSI-CNRS
hamon@limsi.fr
https://perso.limsi.fr/hamon/Teaching/P13/BDA-INFO2-2018-2019/
INFO2 – BDA
1/69Sources des transparents
F. Boufares, LIPN, Université Paris Nord
P. Marcel, LI, Université de Tours
Bernard Espinasse, Ecole Polytechnique Universitaire de
Marseille
Melanie Herschel, Université Paris Sud
2/69Introduction
Quelle quantité d’information ? sous quelle forme ?
Il y a plus de 15 ans !
en 2000 :
entre 1 et 2 ExaOctets par année (1 Eo = 220 To)
90% électronique
taux de croissance annuel de 50 %
en 2003 : 5 Eo en 2002, 92% électronique
Lyman&Varian, 2003 (http://groups.ischool.berkeley.edu/archive/
how-much-info-2003/execsum.htm)
Comment accèder à ces données, tirer partie de ces données ?
→ Les bases de données ne suffisent plus
3/69BD → ED
Des bases de données aux Entrepôts de données
4/69BD → ED
Introduction
Avant les entrepôts de données/Data Warehouses
La majeure partie des applications Bases de Données reposent
aujourd’hui sur trois couches :
La couche la plus externe est celle de qui permet de présenter
les données aux utilisateurs.
Elle est appelée Graphical User Interfaces GUI.
La couche application intermédiaire inclut le programme de
l’application
Elle ne stocke pas les données.
La couche la plus interne gère le stockage des données.
Elle est appelée la couche Base de Données.
5/69BD → ED
Introduction
Couche Présentation Graphical User Interfaces GUI GUI
Couche Application OLTP Application OLTP Application Decision support System
Read, Select
Insert, Update, Delete
Couche Base de Données BD1 BD2
Ressources externes
(file system, ftp, www, ...)
6/69BD → ED
Introduction
Les applications interrogent les données avec, par exemple,
le langage SQL (Select)
et les mettent à jour par l’intermédiaire des opérations
Insert, Update et Delete
qui constituent des transactions.
Celles-ci doivent avoir certaines propriétés ACID (Atomicité,
Cohérence, Isolation et Durabilité)
Ce type d’application est appelé On-Line Transaction Processing
OLTP.
7/69BD → ED
Introduction
Données volumineuses & Besoins nouveaux
Vers les entrepôts de données
→ Systèmes d’Information Décisionnel
Systèmes d’Aide à la Décision (DSS) :
Rapports, Etats, Tableaux de Bord, Graphiques, Synthèses,
Groupement, Agrégat, Résumé ...
(Reporting Tools, Management Information System, Executive
Information System, Decision Support System DSS)
8/69BD → ED
Introduction
Vers les entrepôts de données
Remarques
Contrairement aux applications OLTP, qui consultent et
mettent à jour les données des BD opérationnelles,
les DSS lisent les données seulement pour avoir de
nouvelles informations à partir des données sources
Bénéfice de cette approche : seules les BD opérationnelles ont à
être créées et maintenues
Un ensemble de méta-données est utilisés pour les 2 systèmes.
Les DSS ne nécessitent que des travaux supplémentaires
mineurs.
9/69BD → ED
Introduction
Vers les entrepôts de données
Remarques
Cependant, il y a plusieurs désavantages :
(quand le DSS et les application OLTP se partagent les mêmes BD)
Un DSS ne peut utiliser que les données actuellement stockées
dans les BD
les analyses historiques sont donc souvent impossibles à cause des
opérations de mises à jour qui changent les données historiques
L’utilisation des BD en mode multi-utilisateurs
ce qui implique des opérations de verrouillage des données (Locking
operations) et donc des problèmes de performance
car les requêtes analytiques demandent l’accès à de très grands
nombre de tuples.
10/69BD → ED
Introduction
La solution est de séparer
la BD orientée Transaction
de la BD orientée Aide à la Décision
d’où la naissance du concept
Entrepôt de Données = Data Warehouse.
Les DWH sont physiquement séparés des SGBD opérationnels (BD
opérationnelles)
11/69BD → ED
Introduction
Définition rapide d’un Data Warehouse
Le Data Warehouse est une collection de données orientées sujet,
intégrées, non volatiles, historisées, organisées pour le support d’un
processus d’aide à la décision
Un système de DWH peut être formellement défini comme un
tripletBD → ED
Architecture des DWHs
Méta−données
Extraire
Sources externes
Nettoyer
Transformer
Utiliser
Charger (Load)
Intégrer
Rafraichir
Entrepot de données OLAP
Maintenir
BD opérationnelles
13/69BD → ED
Introduction
Le DWH intègre des données à partir de sources multiples et
hétérogènes
afin de répondre aux requêtes du système d’aide à la décision.
Ce type d’application est appelé On-Line Analytical
Processing OLAP
OLAP permet la transformation des données en informations
stratégiques
14/69BD → ED
Nouveaux concepts/nouvelle perspective
Entrepôt de données
récolte, stockage et gestion efficace des gros volumes de
données
OLAP
requêtes interactives complexes sur ces volumes
Data mining (fouille de données)
extraction automatique de propriétés cachées
données → information → connaissances
15/69BD → ED
Analyse OLAP
(On-Line Analytical processing)
Techniques OLAP :
apparition en recherche dans les années 70
mais développement dans les années 90 dans l’industrie
Réalisation de synthèses, d’analyses et de la consolidation
dynamique de données multidimensionnelles
Manière la plus naturelle d’exploiter un ED étant donné son
organisation multidimensionnelle
16/69BD vs. DWH
Introduction : Comparaison
Pourquoi pas des SGBDs pour les entrepôts de données ?
les 2 systèmes sont performants
SGBD : calibré pour l’OLTP ; méthodes d’accès index,
contrôle de concurrence, reprise
Entrepôt : calibré pour l’OLAP ; requêtes OLAP complexes,
vue dimensionnelle, consolidation
Fonctions et données différentes
Données manquantes : l’aide à la décision (AD) a besoin des
données historiques qui ne se trouvent pas dans les BD
opérationnelles
Consolidation : l’AD a besoin de données consolidées
(agrégats) alors qu’elles sont brutes dans les BD
opérationnelles
17/69BD vs. DWH
Introduction : Comparaison
SGBD hétérogènes vs. Entrepôts de données
Traditionnellement, l’intégration de BD hétérogènes se fait par
le biais de
Wrappers/médiateurs au dessus des BD hétérogènes
Approches orientées requêtes
Quand une requête est posée sur un site client, un
métadictionnaire est utilisé pour la traduire en plusieurs
requêtes appropriées à chacune des BD. Le résultat est
l’intégration de réponses partielles
L’exécution des requêtes demande donc beaucoup de
ressources
Entrepôts de données : approche orientée mise à jour
les informations sont intégrées et stockées pour une
interrogation directe
Plus efficace en coût d’exécution des requêtes
18/69BD vs. DWH
Introduction : Comparaison
BD opérationnelle vs. Entrepôts de données
OLTP (On-Line Transaction Processing)
Exécution en temps réel des transactions, pour
l’enregistrement des opérations quotidiennes : inventaires,
commandes, paye, comptabilité
Par opposition au traitement en batch
OLAP (On-Line Analytical Processing)
Traitement efficace des requêtes d’analyse pour la prise de
décision qui sont par défaut assez complexes (bien qu’a priori,
elles peuvent être réalisées par les SGBD classiques)
19/69BD vs. DWH
Introduction : Comparaison
BD opérationnelle vs. Data Warehouse : OLTP vs. OLAP
Données : courantes, détaillées vs. historiques, consolidées
Conception : modèle ER + application vs. modèle en étoile +
sujet
Vues : courantes, locales vs. évolutive, intégrée
Mode d’accès : mise à jour vs. lecture seule mais requêtes
complexes
20/69BD vs. DWH
Architecture du DWH
Architecture Multi-tiers
Data select
Dictionnaire de (requetes)
OLAP SERVER
Méta−données
100
0
Oracle Express 011
100
11
MVS (TSO, DB2 ...)
Business Objects
(rapports, analyses)
E(xtract)
T(ransform)
L(oad) DataWareHouse
111
0
0
100
00
11
UNIX (Oracle, ...) Oracle 9i (Olap)
SAS
(Datamining)
111
0
000
100
11
Windows (SQL Server, Data Marts
Excel, ...)
Applications en Controle et chargement des données OLAP Outils Front−End
production
21/69BD vs. DWH
Conception logique des DWHs
Données multidimentionnelles
Montant des ventes comme une fonction des paramètres
produits, mois, région
Dimensions : Produit, Lieu, Temps
Chemins de consolidation hiérarchiques
on
Régi
Région Année
Industrie
Pays Trimestre
Catégorie
Produit
Ville Mois
Semaine
Produit
Magasin Jour
Mois
22/69Applications
Domaines d’application
Ceux de l’informatique décisionnelle (Business Intelligence)
pour
aider atteindre les objectifs stratégiques d’une entreprise et
faciliter son pilotage
avoir une connaissance plus approfondie de l’entreprise
anticiper les besoins clients
prendre en compte les nouveaux canaux de distribution (vente
en ligne, etc.)
23/69Applications
Domaines d’application
Informatique décisionnelle
Entrepôt de données
Outils de veille stratégique et de recueil d’information
(intelligence économique)
Aide aux décideurs pour prendre les bonnes décisions sur la
base des données disponibles
Exemples :
Quels sont les 5 produits les plus vendus pour chaque
sous-catégorie de produits qui représente plus de 20% des
ventes dans sa catégorie de produits ?
Quelle est la priorité d’expédition et quel est le revenu brut
potentiel des commandes de livres qui ont les 10 plus grandes
recettes brutes parmi les commandes qui n’avaient pas encore
été expédiées ?
24/69Applications
Applications
Commerce, finance, transport, télécommunications, santé, services,
...
gestion de la relation client
gestion des commandes, des stocks
prévisions de ventes
définition de profil utilisateur
analyse de transactions bancaires
détection de fraudes
...
25/69Applications
Principales applications autour d’un ED
Réalisation de rapports divers (Reporting)
Réalisation de tableaux de bords (Dashboards)
Fouille de données (Data Mining)
Visualisations autour d’un ED (visualizations)
...
26/69Applications
Exemple d’application
Domaine bancaire
Un des premiers utilisateurs des ED
Regroupement des informations relatives à un client pour une
demande de crédit
Lors de la commercialisation d’un nouveau produit :
Mailing ciblés rapidement élaborés à partir de toutes les
informations disponibles sur un client
Recherche de fraudes sur les cartes de crédit :
Mémorisation des mouvements et contrôles a posteriori, pour
détecter les comportements suspects
Échanges d’actions et de conseils de courtages
Déterminer des tendances de marchés grâce à :
la mémorisation de l’historique
une exploitation par des outils décisionnels avancés
27/69Définition d’un DWH
Construction et d’exploitation d’un entrepôt de données
Processus en 3 phases :
1 Construction de la BD décisionnelle
Modélisation conceptuelle des données multiformes et multi-sources
Conception de l’entrepôt de données
Alimentation de l’entrepôt (extraire, nettoyer, transformer, charger)
Stockage physique des données
2 Sélection des données à analyser
Besoins d’analyse de l’utilisateur
Data marts (Magasins de données)
Cubes multidimensionnels
Tableaux ou tables bidimensionnels
3 Analyse des données
Stastiques et reporting, OLAP, Data Mining
28/69Définition d’un DWH
Présentation des couches
Couche Présentation Graphical User Interfaces GUI GUI
Couche Application OLTP Application OLTP Application Decision support System
Insert, Update, Delete Read, Select
Couche Base de Données BD2
BD1
Target DataBase
Load
DataWareHouse
Ressources externes
(file system, ftp, www, ...)
29/69Définition d’un DWH
Architecture du DWH
Architecture Multi-tiers
Data select
Dictionnaire de (requetes)
OLAP SERVER
Méta−données
100
0
Oracle Express 011
100
11
MVS (TSO, DB2 ...)
Business Objects
(rapports, analyses)
E(xtract)
T(ransform)
L(oad) DataWareHouse
111
0
0
100
00
11
UNIX (Oracle, ...) Oracle 9i (Olap)
SAS
(Datamining)
111
0
000
100
11
Windows (SQL Server, Data Marts
Excel, ...)
Applications en Controle et chargement des données OLAP Outils Front−End
production
30/69Définition d’un DWH
Opérations
Extraction (Extraction) : Ces opérations permettent de filtrer les
données à partir de données sources (BD, fichiers, sites web...) dans
des BD temporaires.
Transformation (Transformation) : Ces opérations permettent de
transformer les données extraites dans un format uniforme.
Les conflits entre les modèles, les schémas et les données sont
résolus durant cette phase.
Chargement (Load) : Ces opérations permettent de charger les
données transformées dans la BD cible.
La BD cible est souvent implantée avec un SGBD relationnel-objet.
Agrégat et Groupement (Agregating and Grouping) : La BD cible
doit permettre de stocker les données opérationnelles et les données
issues de calculs.
31/69Architecture
Architecture
Objectifs :
regrouper les données sources
concevoir le schéma de l’entrepôt
remplir l’entrepôt
maintenir l’entrepôt
32/69Architecture fonctionnelle
Architecture fonctionnelle de l’entrepôt
Les données d’un entrepôt se structurent suivant
un axe synthétique : établissement d’une hiérarchie
d’agrégation incluant
les données détaillées : les événements les plus récents
les données agrégées : synthèse des données détaillées
les données fortement agrégées : synthèse à un niveau
supérieur des données agrégées
un axe historique
incluant les données détaillées historisées représentant les
événements passés
→ Stockage des méta-données : informations concernant les
données de l’ED (provenances, structures, méthodes utilisées pour
l’agrégation, ...)
33/69Architecture fonctionnelle
Entrepôts et magasins de données
Data Warehouses et Data marts
Entrepôts de données
Collecte l’ensemble de l’information utile aux décideurs à partir
des sources de données (BD opérationnelle, BD externes, ...)
Centralisation de l’information décisionnelle
Garantie de l’intégration des données extraites et de leur
pérennité dans le temps
Magasins de données
Orientés sujet
Aide efficace aux processus OLAP
Extraction d’une partie des données utiles :
pour une classe d’utilisateurs ou
pour un besoin d’analyse spécifique
34/69Architecture fonctionnelle
Dictionnaire et méta-données
Dictionnaire contenant des informations (méta-données) sur :
toutes les données de l’ED
chaque étape de la construction de l’ED
le passage d’un niveau de données à un autre (exploitation de
l’ED)
Rôle : définition, fabrication, stockage, accès et présentation
des données
35/69Données sources
Données sources
Les données des entreprises sont généralement :
Surabondantes
Eparpillées
Peu structurées pour l’analyse
Modifiées quotidiennement
Problème : Prise de décision difficile
Solution : Utilisation d’outils et de techniques visant à préparer les
données pour l’analyse Data warehousing
Il s’agit d’une technique visant à extraire des données de
différentes sources afin de les intégrer selon des formats
plus adaptés à l’analyse et la prise de décision
→ Problématique d’intégration et définition de wrappers
36/69Données sources
Données sources hétérogènes
Nécessité d’intéger des données hétérogènes, modifiées
quotidiennement
BD
relationnelles
objets
distribuées
fichiers textes
documents HTML, XML
bases de connaissances
...
Mais aussi des représentations de données et de noms de
champs/colonnes hétérogènes
37/69Alimentation de l’ED
Processus d’alimentation d’un ED
Entreposage des données
Rôle de l’alimentation de l’entrepôt
rassembler de multiples données sources souvent
hétérogènes
homogénéiser les données sources
Homogénéisation réalisée selon des règles précises
Les règles d’homogénéisation sont :
mémorisées sous forme de méta-données stockées dans le
dictionnaire de données
utiliser pour assurer des tâches d’administration et de
gestion des données entreposées
38/69Alimentation de l’ED
Processus d’alimentation d’un ED
4 étapes :
1 Sélection des données sources
2 Extraction des données
3 Nettoyage et Transformation
4 Chargement
Etapes 1 et 2 : Jusqu’à 80 % du temps de développement d’un
entrepôt
→ outil : Oracle Warehouse Builder (OWB)
39/69Alimentation de l’ED
Extraction des données
Un extracteur (wrapper) est associé à chaque source de données
Sélection et extraction des données
Formatage des données dans un format cible commun
en général, le modèle Relationnel
Utilisation d’interfaces comme ODB, OCI, JDBC
40/69Alimentation de l’ED
Transformation
Objectif : suppression des incohérences sémantiques entre les
sources, problématique lors de l’intégration
des schémas
des données
41/69Alimentation de l’ED
Transformation
Résolution des problèmes survenant lors de l’intégration des
schémas
Demande une solide connaissance de la sémantique des
schémas
Peu traitée par les produits du marché
Nombreux travaux de recherche
Opération généralement réalisée à la main...
42/69Alimentation de l’ED
Chargement des données
Objectif : Stockage des données nettoyées et préparées dans la BD
opérationnelle (ODS)
Opération :
risquant d’être assez longue
plutôt mécanique
la moins complexe
Mais il est nécessaire de définir et mettre en place :
des stratégies pour assurer de bonnes conditions à sa
réalisation
une politique de rafraîchissement
43/69Alimentation de l’ED
Chargement des données
Définitions de vues relationnelles sur les données sources
Matérialisation des vues dans l’entrepôt
Mais aussi, préparation à la restitution
tris
consolidations (pré-agrégation)
indexation
partitionnement des données
enregistrement de méta-données
...
44/69Alimentation de l’ED
Préparation à la restitution
Agrégation
Calcul de vues agrégées
Définition des indexes
Stockage dans le CDW
Personnalisation
Construction de magasin de données (Data Marts)
Construction de cubes de données
Construction des présentations demandées par les utilisateurs
45/69Modélisation
Modélisation multidimensionnelle
Lien direct entre les analyses décisionnelles (OLAP) et une
modélisation de l’information conceptuelle :
proche de la perception qu’en a l’analyste
basée sur une vision multidimensionnelle des données
Modèle multidimensitionnel : les données sont vues comme des
data cubes
Un cube de dimension n est dit un cuboïde
Le treillis des cuboïdes d’un entrepôt de données forme un
data cube
La modélisation multidimensionnelle a donné naissance aux
concepts de fait et de dimension (Kimball 1996)
46/69Modélisation
Cube de données
47/69Modélisation
Exemple de treillis de cube
48/69Modélisation
Cube de données
Sujet analysé : un point dans un espace à plusieurs dimensions
Organisation des données pour mettre en évidence le sujet
analysé et les différentes perspectives de l’analyse
data cube (par exemple, les ventes) : vision des données sur
plusieurs dimensions
49/69Modélisation
Concept de fait
Un fait :
modélisation du sujet de l’analyse
Mesures correspondant aux informations de l’activité analysée
Mesures numériques, généralement valorisées de façon
continue. On peut
les additionner
les dénombrer
calculer le minimum, le maximum ou la moyenne
Exemple : le fait de Vente peut être constitué des mesures
d’activités suivantes :
quantité de produits vendus
montant total des ventes
50/69Modélisation
Concept de dimension
Axes ou perspectives caractérisant es mesures de l’activité d’un fait
Une dimension :
modélisation un axe d’analyse
nécessité pour chaque dimension, de définir ses différents
niveaux de détail
→ Définition de une (ou plusieurs) hiérarchie(s) de paramètres
se compose de paramètres correspondant aux informations
faisant varier les mesures de l’activité
Dans l’exemple précédent :
Analyse du fait Vente suivant différentes perspectives correspondant
à trois dimensions :
la dimension Temps
la dimension Geographie
la dimension Categorie
51/69Bilan
Conclusion et perspectives
Deux tendances actuelles
datamarts
dataweb
construction du Data Warehouse : processus long et difficile
Construction progressive par datamarts
Avantage : rapide
Inconvénient : risque de cohabitation de datamarts incohérents
Dataweb
Ouverture du data warehouse au web
52/69Bilan
Plus loin...
Big data warehouses
Volume
Optimisation/parallélisation des agrégations
OLAP dans un cloud
Variété
Nouveaux modèles multidimensionnels et opérateurs
d’agrégation
Entrepôts NoSQL
Vélocité
Travailler en mémoire : problème de l’explosion dimensionnelle
Fonctions d’oubli
Véracité
Qualité des données sources
Sécurité des données entreposées
53/69NoSQL
NoSQL
54/69NoSQL
Sources des transparents
Bernd Amann, LIP6
Bernard Espinasse, Ecole Polytechnique Universitaire de
Marseille
Olivier Guibert, Université de Bordeaux
Anne-Cécile Caron, Université de Lille
55/69NoSQL
Introduction
Constats :
De plus en plus de donnnées disponibles ou à manipuler
très grandes plateformes
applications Web (Google, Facebook, Twitter, Amazon, ...)
Nécessite de la gestion des données de manière distribuée
Le respect des propriétés ACID (Atomicité, Cohérence,
Isolation et Durabilité) n’est pas possible dans un
environnement distribué
Aussi, manipulation
de données complexes, hétérogènes, non structurées
de très grands volumes de données (Big Data)
56/69NoSQL
Evolutions de la gestion des données
Nouvelles Données :
Web 2.0 : Facebook, Twitter, news, blogs, ...
LOD : graphes, ontologies, ...
Flux : capteurs, GPS, ...
→ Très gros volumes, données pas ou faiblement structurées
Nouveaux Traitements :
Moteurs de recherche
Extraction, analyse, ...
Recommandation, filtrage collaboratif, ...
→ Transformation, agrégation, indexation
Nouvelles Infrastructures :
Cluster, réseaux mobiles, microprocesseurs multi-coeurs, ...
→ Distribution, parallélisation, redondance
57/69NoSQL
Augmentation du volume de données
w3resource.com/mongodb/nosql.php
58/69NoSQL
Limites de SGBD relationnels/traditionnels
Faible efficacité lorsque les volumes de données sont importants car
Transaction respectant les propriétés ACID
Requêtes LMJ réalisées séquentiellement et préservant
l’intégrité des données
→ Gestion des transaction complexe ayant un impact sur les
performances
Modèle ER flexible mais peu adapté aux données
non-structurées
→ peu performant et couteux en temps de développement
Matériel et logicieux coûteux et compétences en optimisation
peu répandues
→ Nécessité de distribuer les traitements
59/69NoSQL
NoSQL
Définition de systèmes « NoSQL » (not only SQL)
Pour répondre à l’augmentation du volume de donnnées à
traiter :
Spécialisation des systèmes
Systèmes sur mesure
Pas d’utilisation de SQL comme langage de requête
Généralement des modèles de données différents :
Modèle Document
Modèle Colonne
Modèle clé/valeur
Modèle Graphe
→ Théorème CAP (Cohérence, Disponibilité, Pannes)
(Brewer, 2000)
60/69NoSQL
Théorème CAP
w3resource.com/mongodb/nosql.php
61/69NoSQL
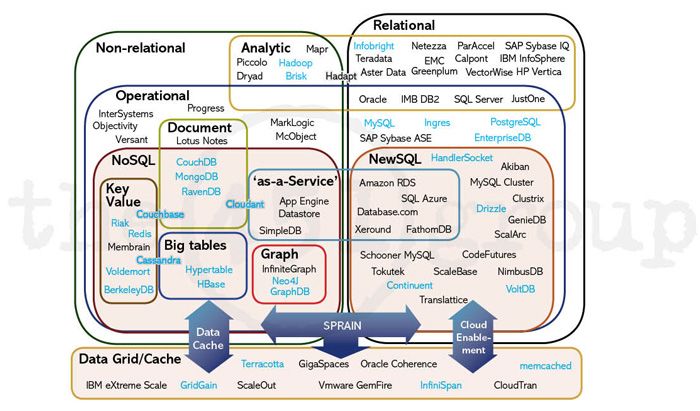
Systèmes NoSQL
62/69NoSQL
SGBD NoSQL
Définition
SGBD non fondé sur
l’architecture des SGBDR
open source
distribué
horizontally scalable (montée en charge par ajout de serveurs)
63/69NoSQL
SGBD NoSQL
Simplification en renonçant aux fonctionnalités classiques des
SGBDR :
Redondance (via réplication)
Pas forcément de schéma normalisé, initialement voire à terme
Pas de tables mais des collections
Rarement du SQL mais API simple ou langage spécialisé
Pas forcément de jointure mais multiplication des requêtes,
cache/réplication/données non normalisées, données imbriquées
Transactions pas forcément ACID mais plutôt BASE
Résisitance aux pannes (P) s’impose pour un système distribué :
AP (accepte de recevoir des données éventuellement
incohérentes)
CP (attendre que les données soient cohérentes)
64/69NoSQL
SGBD NoSQL
Gestion des mégadonnées (big data) du web, des objets connectés,
etc.
Structure des données hétérogène et évolutive
Données complexes et pas toujours renseignées
Environnement distribué : données répliquées et accédées d’un peu
partout (dans le monde), traitement répartis
Techniques de partionnement des BD : sharding, hachage cohérent
(consistent hashing)
Contrôle de concurrence multi-version (Multi-Version Concurrency
Control MVCC)
Adaptation du protocole Paxos
Performances linéaires avec la montée en charge (les requêtes
obtiennent toujours aussi rapidement une réponse)
65/69NoSQL
Classification de systèmes
Types de données : tables, clés/valeurs, arbres, graphes,
documents
Paradigme (langages) : MapReduce (PIG, Hive)
API / Protocole : JSON/REST
Persistence : mémoire, disque, cloud...
Gestion de concurrence / cohérence
Réplication, protocoles
Langage d’implémentation, ...
Voir https://db-engines.com/en/ranking
66/69Fondements des systèmes NoSQL
Fondements des systèmes NoSQL
Sharding : partitionnement sur plusieurs serveurs
Consistent hashing : partitionnement des données sur
plusieurs serveurs eux-mêmes partitionnés sur un segment
Map Reduce : modèle de programmation parallèle permettant
de paralléliser tout un ensemble tâches à effectuer sur un
ensemble de données,
MVCC (Contrôle de Concurrence Multi-Version) : mécanisme
permettant d’assurer le contrôle de concurrence
Vector-Clock (horloges vectorielles) : mises à jour
concurrentes en datant les données par des vecteurs d’horloge
67/69Fondements des systèmes NoSQL
Conclusion
On a besoin de SQL et de NoSQL
NoSQL = not only SQL
Principe CAP
Importance de noSQL
Analyse de données
Passage à l’échelle
Parallélisation / partionnement verticale
68/69Fondements des systèmes NoSQL
Conclusion
Les SGBDR en font trop, alors que les produits NoSQL
font exactement ce dont vous avez besoin (Travis, 2009)
Gestion des BD géantes des sites web de très grande audience
Exemple des SGBD d’annuaires : grande majorité des accès aux BD
consistent en lectures sans modification (ainsi, seule la persistance
doit être vérifiée)
« Consensus » actuel :
Les SGBD NoSQL ne replacent pas les SGBDR mais les complètent
en palliant leurs faiblesses
69/69Vous pouvez aussi lire