BIG DATA EN SANT E AVEC LA CAISSE NATIONALE D'ASSURANCE MALADIE GDR MADICS - MARSEILLE S. GA IFFAS
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Big data en santé avec la Caisse Nationale
d’Assurance Maladie
GdR MaDics – Marseille
S. Gaı̈ffas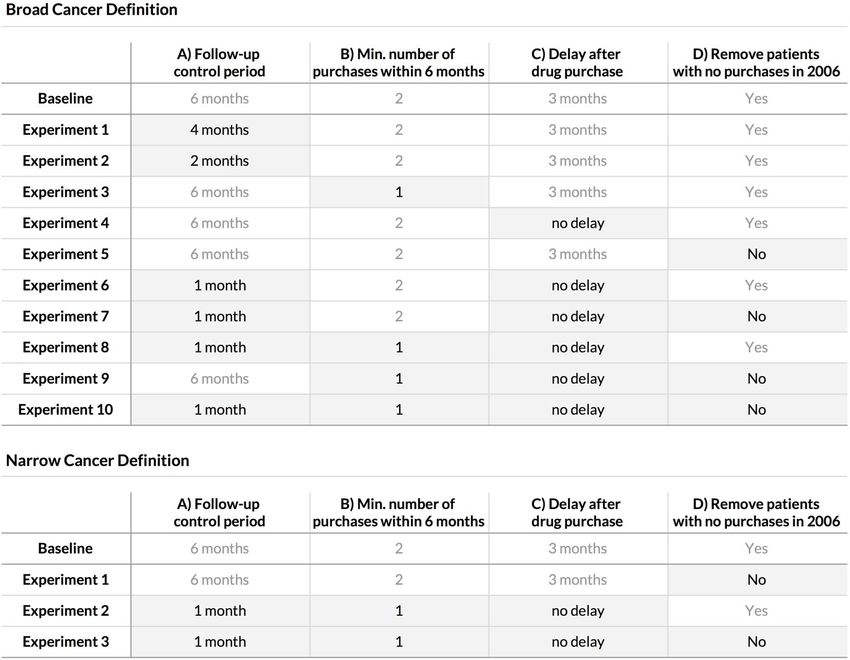
L’équipe
Chercheurs confirmés (temps partiel)
X : E. Bacry (X-CNRS), A. Guilloux (Univ. d’Evry), S. G. (X)
CNAMTS : Très nombreuses personnes impliquées
Temps complet
Bio-statisticienne: F. Leroy (CNAMTS)
Ingénieurs: F. Ben Sassi (CNAMTS), P. Burq (X), C. Giatsidis (X),
S. Kumar (X), D. de Paula Silva (X)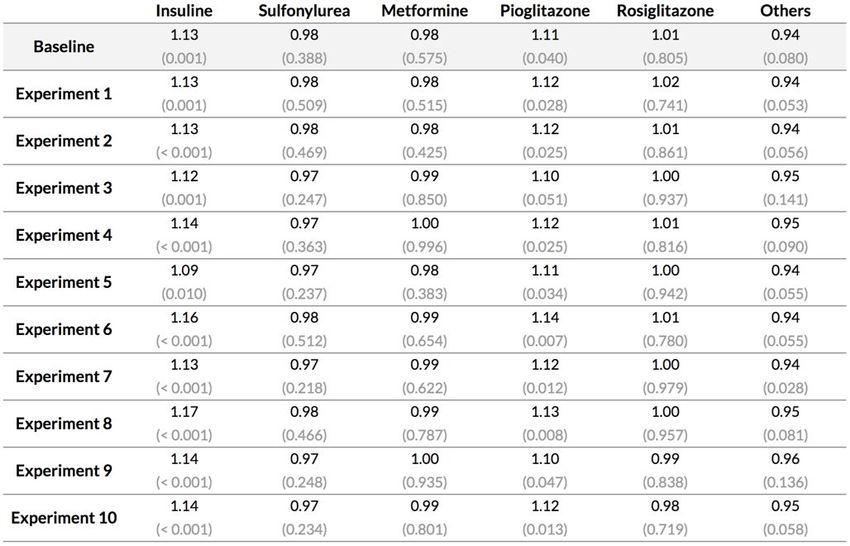
Infrastructure de la CNAMTS
1. Infrastructure machine : architecture machine “verticale”
propriétaire (Exadata)
2. Infrastructure base de données : base relationnelle SQL (800
tables, plusieurs centaines de To) propriétaire (Oracle)
3. Infrastructure logicielle : logiciel propriétaire (SAS)
=⇒ Inadéquation pour de nouvelles approches type “big data”
Architecture très fermée limitant la recherche méthodologique
Architecture peu adaptée au calcul distribué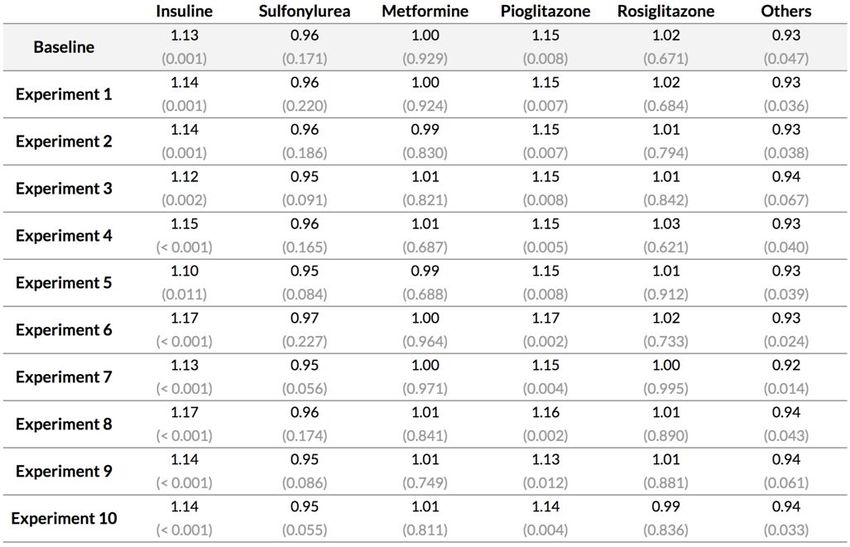
Le partenariat entre Polytechnique et la CNAMTS
Partenariat de recherche sur 3 ans (2015-2017)
But : tester le potentiel des techniques/méthodologies “big data” sur les
données du SNIIRAM/PMSI
Efficacité/efficience des parcours de soins
Signaux faibles en pharmaco-épidémiologie
Pharmacovigilance
...
Alors que :
SNIIRAM/PMSI n’est pas fait pour ca (à l’origine) !
C’est la base qui rembourse les soins aux franccais
Donc une table orientée “évenements santés”
Mais :
Extrêmement riche en informations
Une des plus grande base de données orienté santé du monde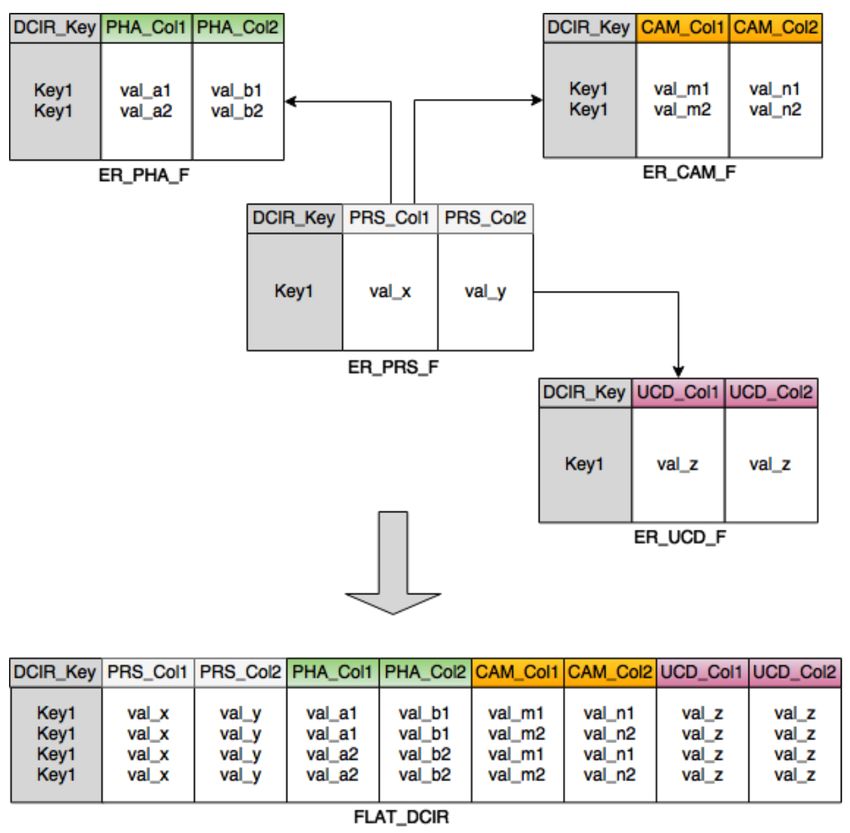
Infrastructure “horizontale”
Two (almost) duplicate big data clusters
“Scalable” architecture:
distributed data and
computations
4 masters
15 slaves
240 cores
1.9To RAM
480To (120 hard-drives)
HDFS (triple
replication)
Spark, Scala
Only open-source
technology
Preprocessing des données
Compréhension
Aplatissement
Organisation
Stockage distribué
Format orienté colonne
parquet.apachage.org
Open source
Production en mode “agile”
Etape cruciale : passage d’un stock-
age de la donnée idéal pour du SQL
(random access) à un stockage idéal
pour une lecture séquentielle de la
donnée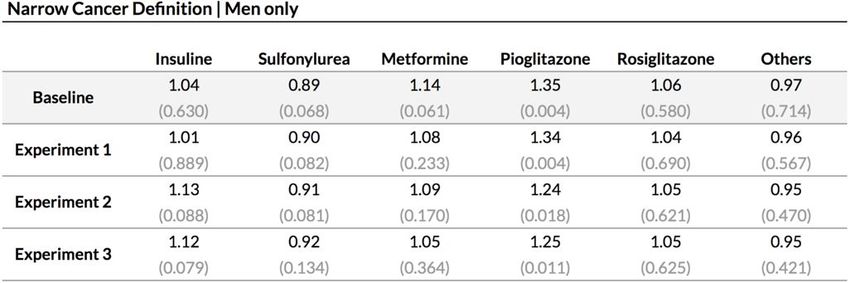
Architecture logicielle
Featuring. Transformation la donnée brute en une matrice numérique
utilisable par les algorithmes d’apprentissage.
Codé en scala
Utilise le framework spark pour distribuer les calculs
Dépend du modèle et du cas concret à étudier
Choix du modèle. Inférence statistique
Utilisation de R dans le cas de modèles “classiques”
Librairie tick (Python et C++)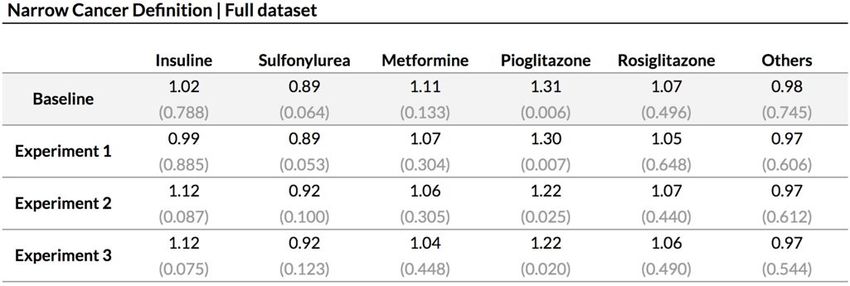
Software: tick library
Python 3 et C++11
Open-source (BSD-3 License)
pip install tick (on MacOS and Linux...)
https://x-datainitiative.github.io/tick
Statistical learning for time-dependent models
Point processes (Poisson, Hawkes), Survival analysis, GLMs
(parallelized, sparse, etc.)
A strong simulation and optimization toolbox
Partnership with Intel (use-case of a new processor with 180 cores)
Contributors welcome!
Software: tick library

Cancer de la vessie pour une cohorte de diabétiques
Le “projet pilote” en pharmaco-vigilance
But : développer une méthode de “screening” permettant un premier
balayage automatique sur plusieurs médicaments.
6= validation d’hypothèse
Etape simplifiée de préparation de cohorte
Application
Cohorte : diabétiques de type 2
Effet indésirable : Cancer de la vessie
−→ identification par screening du Pioglitazone (retiré du marché en
2011)Cancer de la vessie pour une cohorte de diabétiques
Quelques chiffres
2.5 millions de personnes
4 ans d’historique
1.3 To (' 250Go par an)
2 milliards de “lignes” (500 millions de lignes par an)
“Applatissement de la base” ' 40 minutes (depuis spark 2.1)
Featuring ' 10mnRésultats obtenus par un algorithme “standard”
Modèle de Cox (survie) ⇒ validation d’hypothèse
Papier de référence : Pioglitazone and risk of bladder cancer among
diabetic patients in France : a population-based cohort study,
A.Neumann, A.Weill, P.Ricordeau, J.P.Fagot, F.Alla - H.Allemand
Diabetologia 2012.
But de l’étude :
Reproduction des résultats
Etude de la stabilité par rapport aux paramètres de construction de
cohorteLes paramètres de construction de la cohorte
1. Définition du cancer
“Broad” : diagnostic C67
Definitions (2/5)
“Narrow” : C67 + radiothérapie + chimiothérapie + ...
● Follow-up Control Period (A)
2. Période○ deDefined
controle du of
by a number “Follow up”
months after first A10 drug purchase
○ Exposures starting within this control period are considered to be started
Patients dont le cancer est diagnostiqué avant ou pendant la période
at follow-up start
A sont○écartés
Patients with a bladder cancer diagnostic within this control period or
Défaut : before
6 mois it are removed from the cohort
○ Default: 6 months
7Les paramètres de construction de la cohorte (suite)
Definitions (3/5)
3. Minimum d’achats
● Minimum number of purchases within 6 months (B)
Un patient est considéré
○ A patient is consideredcomme exposé
to be exposed to a à une molécule
molecule if he boughts’il
a a acheté
un médicament contenant
drug containing cette
it “B” times molécule
within B fois
an “N” months time en N mois.
window.
○ Default: 2 purchases, 6 months
Défaut : B = 2, N = 6 mois
8Les paramètres de construction de la cohorte (suite et fin)
Definitions (4/5)
4. Délai d’exposition
● Delay
Nombre de After
mois Purchase
après la (C)
dernière prise de médicament pour que le
Number
patient○ soir of monthscomme
considéré after a patient is considered to be exposed for the
exposé.
actual exposure period to start
Défaut○: Default:
3 mois3 months
5. Censure des patients qui ne prennent plus d’antidiabétiques
Si plus de médicaments pendant plus de 4 mois, censure 9
Défaut : OuiPlan d’expérience avec un algorithme “standard” (Cox PH)
Experiments
11Broad cancer : Résultats obtenus avec Cox PH
Results - Broad Cancer Definition (Full Dataset)
12Broad cancer (hommes seulement) : Résultats obtenus avec Cox PH
Results - Broad Cancer Definition (Men Only)
13Narrow cancer : Résultats obtenus avec Cox PH
Results - Narrow Cancer Definition
14Un nouveau modèle de screening
Un modèle SCCS :
Un modèle “self-controlled case-series” (SCCS) : on ne garde dans
la cohorte que les personnes ayant eu un cancer
Travail de préparation de cohorte très simplifiée : définition de
l’exposition
Modèle longitudinal (features et labels)
On estime l’impact (en fonction du temps) de l’exposition à un
médicament sur la probabilité de développer un cancer à tel momentModèle case-series
Un nouveau modèle de screening
● Un modèle “case-series” : on ne garde dans la cohorte que les personnes
ayant eu un cancer
● Travail de préparation de cohorte très simplifiée : définition de l’exposition.
● On estime la probabilité d’avoir un cancer en fonction du temps après une
exposition
Deux à un anti-diabétique
exemples de modèles d’exposition
● Deux modèles
Modèle “Exposition simple”
Modèle “Expositions multiples”
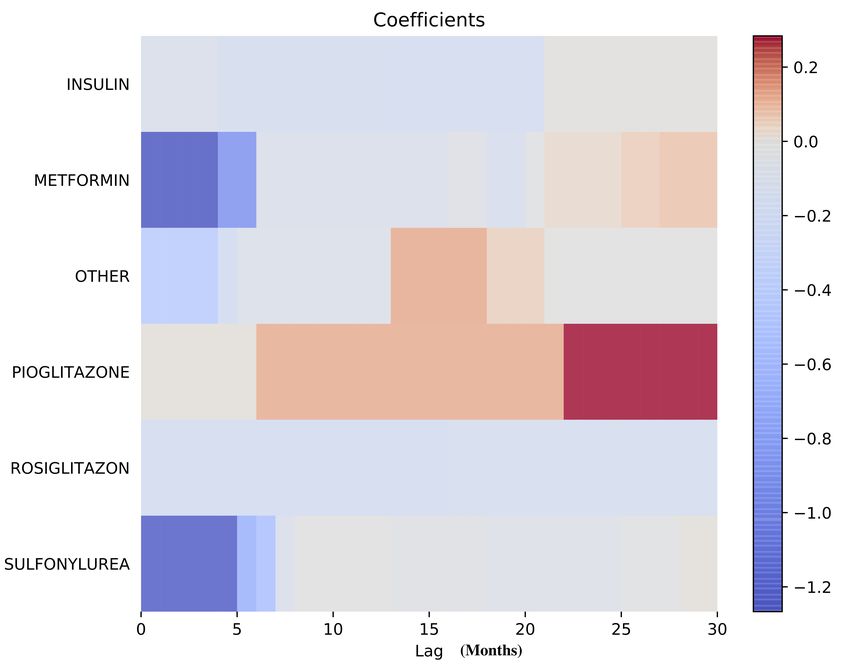
15Résultats obtenus par le nouveau modèle
Résultats obtenus par le nouveau modèle
Methodology
Setting
We have individuals i = 1, . . . , n
Time [0, T ] is partitioned in intervals I1 , . . . , IB (length=month,
week or day)
We observe the number of adverse events yi,b ∈ N
PB
We put ni = b=1 yi,b = total number of adverse events of
individual i
1 d
We observe longitudinal features xi,b = (xi,b , . . . , xi,b ) ∈ Rd over
time intervals b = 1, . . . , B (drugs exposures, etc.)
We observe “static” features zi = (zi1 , . . . , zip ) ∈ Rp (gender, age if
B is small, etc.)Methodology
Autoregressive features
The intensity of occurrence of adverse events at time b depends on
feature j via:
K
X −1
θkj xi,b
j,k
k=0
where:
θjk = effect of feature j when exposure occurred k time intervals
before the current one
j,k
xi,b = exposure of individual i to drug j that occurred k intervals
before interval b
Leads to a translation-invariant parametrization of the model
no time realignment is required
a big issue in SCCS literature (where only one type of exposure, i.e.
a single molecule is used !)Methodology
Notation
b stands for the “current index”
k stands for the “lag”
j,k
xi,b = 0 for any k ≥ b
We define the d × B matrix X i,b with entries
j,k
(X i,b )j,k = xi,b
for j = 1, . . . , d, k = 0, . . . , B − 1, i = 1, . . . , n and b = 1, . . . , B.
We define also
d B−1
X X
hθ, X i,b i = θkj xi,b
j,k
j=1 k=0Methodology
Self-controlled case series or conditional Poisson regression
Trick is to exploit the ordered statistic property of Poisson processes
Use a model on the conditional distribution of (yi,1 , . . . , yi,B )|ni ,
PB
where ni = b=1 yi,b
Distribution of (yi,1 , . . . , y1,B ) conditionally on ni , xi is
e hX i,1 ,θi e hX i,B ,θi
Multinomial ni , PB hX i,b0 ,θi
, . . . , PB hX i,b0 ,θi
b 0 =1 e b 0 =1 eMethodology
Namely, we have that
B yi,b
ni ! Y e hX i,b ,θi
P(yi,1 , . . . , y1,B |ni , xi ) = QB PB hX i,b0 ,θi
b=1 yib ! b=1 b 0 =1 e
Important remark
Constant effects (independent on b, such as the zi ) are killed by the
conditioning with respect to ni , since whenever
>
λi,b = e hX i,b0 ,θi+β z+cb
,
we have
λi,b e hX i,b ,θi
PB = PB
b 0 =1 λi,b0 b 0 =1 e hX i,b0 ,θiMethodology
Penalization
We want to consider a large number of lags K , but we want to
“smooth” the time-adjacent coefficients θ1j , . . . , θBj
We use “group” total-variation penalization
Algorithm
We minimize the following over θ
n B B
1 XX X
hX i,b0 ,θi
− δi yi,b hX i,b , θi − log e
n 0
i=1 b=1 b =1
d B−1
X X
+λ |θkj − θk−1
j
|
i=1 k=1Methodology
Tips and tricks
Stratified V -fold cross-validation for λ
Very fast solver: SGD with variance reduction
Fast proximal operator for total-variation
Exploit sparsity of the X i,b
Available generalizations
Right-censoring
Other types of featuring in X i,b
Features product (joint exposures)
Next generalizations
Confidence intervals
Multi-task (many adverse events at the same time)
Non-case seriesEn cours: étude sur les chutes de personnes agées
Cohorte : personnes agées
Médicaments : large classe (plusieurs dizaines)
Effet indésirable : chute (fracture)
Quelques chiffres
12 millions de personnes (versus 2.5 pour projet pilote)
' 1.6To par an (versus 250Go pour projet pilote)
2 milliards de ligne par an (versus 400 millions pour projet pilote)En cours: étude sur les chutes de personnes agées
Quelques challenges
Scalabilité de la pipeline
Définition de l’événement “chute” à partir de remboursements
générés par des fractures
Définition des molécules à surveiller
Adaptation du modèle aux expositions répétées pour la détection
d’effets à court termeMerci !
Vous pouvez aussi lire

















































