Comprendre et utiliser les word embeddings - CLLE-ERSS
←
→
Transcription du contenu de la page
Si votre navigateur ne rend pas la page correctement, lisez s'il vous plaît le contenu de la page ci-dessous
Comprendre et utiliser les word embeddings Bénédicte Pierrejean Université Toulouse Jean Jaurès - CLLE-ERSS
Objectifs
• Introduction à la sémantique distributionnelle
• Introduction aux word embeddings
• Utilisation de divers outils de développement
• Manipulation des words embeddings (entraı̂ner un modèle,
interroger un modèle etc.)
1Sémantique Distributionnelle et Espaces Vectoriels
Sémantique Distributionnelle
Sémantique distributionnelle
Des mots apparaissant dans contextes similaires ont des sens
proches (Harris, 1954)
“You shall know a word by the company it keep”, (Firth, 1957)
Principe de l’approche distributionnelle
Speech and Language Processing, Jurafsky & Martin, 3rd ed. draft
2Modèles distributionnels
• Représentation du sens des mots sous forme de vecteurs (=
liste de nombres)
Modèles à base de fréquences
• Construits à partir des fréquences des cooccurences
• Vecteurs peu denses et très gros
Speech and Language Processing, Jurafsky & Martin, 3rd ed. draft
3Modèles distributionnels
Modèles prédictifs / dense vectors / word embeddings /
plongements de mots
• Vecteurs denses avec peu de dimensions
• Plus facile à intégrer dans des modèles de deep learning
https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
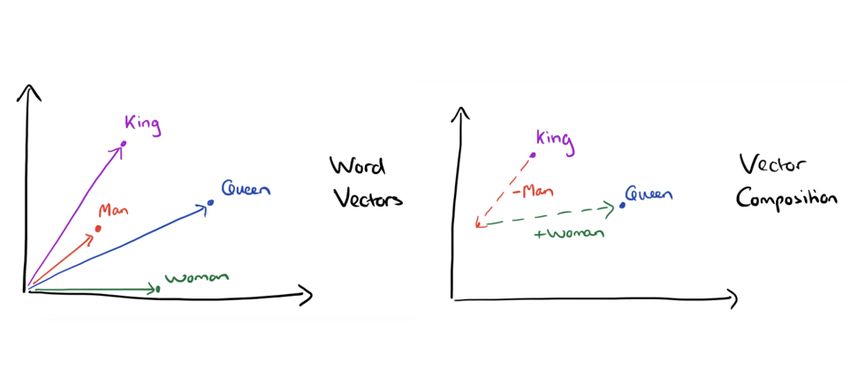
4Opérations mathématiques
https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
• vecteur(king) - vecteur(man) + vecteur(woman) =
vecteur(queen)
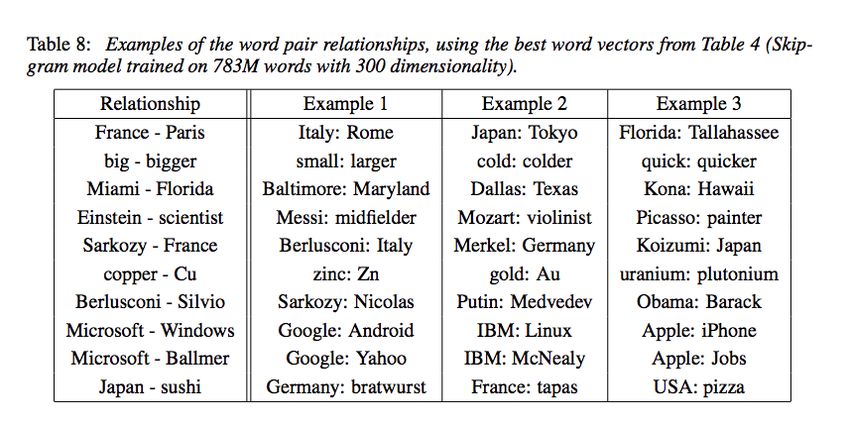
5Analogies
Mikolov et al., 2013
6Similarité et voisins
Cosinus
Speech and Language Processing, Jurafsky & Martin, 3rd ed. draft
• Score cosinus allant de 0 (mots très différents) à 1 (mots très
similaires).
• Permet de récupérer les voisins d’un mot donné.
7Exemple calcul cosinus
petit gris orange
chat 4 3 1
chien 2 2 0
abricot 1 0 5
Calcul de similarité de chat/chien
4∗2+3∗2+1∗0 14
cos(chat, chien) = √ √ = √ √ = 0.97
42 2 2 2 2
+3 +1 2 +2 +0 2 26 8
Calcul de similarité de chat/abricot
4∗1+3∗0+1∗5 9
cos(chat, abricot) = √ √ = √ √ = 0.34
42 2 2 2 2
+3 +1 1 +0 +5 2 26 26
8A vous de jouer !
petit gris orange
chat 4 3 1
chien 2 2 0
abricot 1 0 5
Calcul de similarité de chien/abricot
9A vous de jouer !
petit gris orange
chat 4 3 1
chien 2 2 0
abricot 1 0 5
Calcul de similarité de chien/abricot
2∗1+2∗0+0∗5 2
cos(chien, abricot) = √ √ = √ √ = 0.14
22 2 2 2 2
+2 +0 1 +0 +5 2 8 26
10Word Embeddings
Quels systèmes pour entraı̂ner des word embeddings ?
Différentes méthodes
• word2vec (Mikolov et. al, 2013)
• Continuous Bag of Words (CBOW)
• Skip-Gram with Negative Sampling (SGNS)
• fastText (Bojanowski et al., 2017)
• Embeddings de n-grams
• Glove (Pennington et al., 2014)
11word2vec (Mikolov et al., 2013)
• Rapide à entraı̂ner
• Facilement accessible (code C, librairie python gensim,
vecteurs pré-entraı̂nés etc.)
12word2vec : CBOW
Prédiction de la probabilité qu’un mot apparaisse étant donné les
mots qui l’entourent (contexte)
13
Mikolov et al., 2013word2vec : Skip-Gram with Negative Sampling (SGNS)
Prédiction des contextes à partir d’un mot cible
Mikolov et al., 2013
14fastText (Bojanowski et al., 2017)
• Motivation : améliorer les représentations vectorielles des
mots pour les langues morphologiquement riches
• Représentation vectorielles de n-grams
• Un mot est représenté par la somme des vecteurs de ses
n-grams
• Avantage : on peut obtenir une représentation pour un mot
qui n’existait pas dans le corpus d’entraı̂nement
• 2 algorithmes : Skip-Gram et CBOW
15Utilisation des embeddings
Nombre d’articles scientifiques sur arXiv ayant le mot “embedding”
dans leur titre
16Systèmes inspirés/dérivés de word2vec
• word2vecf (Levy & Goldberg, 2016) : intégration de
dépendances syntaxiques dans les contextes utilisés pour
entraı̂ner les embeddings
• Dict2vec (Tissier et al., 2017) : utilisation de dictionnaires
pour entraı̂ner des embeddings
• Nonce2vec (Herbelot & Baroni, 2017) : apprentissage de
nouveaux mots sur très petits corpus
etc.
17Autres études
• Corpus diachroniques (Hamilton et al., 2016)
• Projet Evolex (Gaume et al., 2018)
18Entraı̂ner des word embeddings avec gensim
Pré-requis
Nécessaire pour ce cours
• avoir Linux ou Mac
• Python 3
• virtualenv
• avoir créé un environnement virtuel pour ce cours
• avoir installé gensim dans l’environnement virtuel créé
• avoir installé jupyter lab dans l’environnement virtuel
19Lancer Jupyter Lab
• Activer l’environnement virtuel que vous aviez précédemment
créé grâce à la commande :
source chemin env/bin/activate
• Aller dans lequel vous avez placé le jupyter notebook utilisé
pour ce cours
cd dossier contenant jupyter notebook
• Lancer Jupyter lab
jupyter lab
20gensim - Fonctions utiles
Récupérer les voisins sémantiques d’un mot
model.wv.most similar("cat")
model.wv.most similar("cat", topn=5)
Rang d’un voisin donné pour un mot donné
model.wv.rank("cat", "dog")
Calcul du score cosinus entre 2 mots
model.wv.similarity("cat", "dog")
Analogies
model.wv.most similar(positive=["woman", "king"],
negative=["man"])
21Visualisation des word embeddings
Embedding Projector - Tensorflow
• Interface qui permet de visualiser des embeddings
• Méthodes de réduction de dimensions (PCA et t-SNE)
• Possibilité de charger ses propres vecteurs
• http://projector.tensorflow.org/
22References
Bojanowski, P., Grave, E., Joulin, A., and Mikolov, T. (2016). Enriching Word Vectors with Subword Information.
In Emnlp, volume 91, pages 28–29.
Gaume, B., Tanguy, L., Fabre, C., Ho-Dac, L.-M., Pierrejean, B., Hathout, N., Farinas, J., Pinquier, J., Danet, L.,
Péran, P., De Boissezon, X., and Jucla, M. (2018). Automatic analysis of word association data from the
Evolex psycholinguistic tasks using computational lexical semantic similarity measures. In 13th International
Workshop on Natural Language Processing and Cognitive Science (NLPCS), Krakow, Poland.
Hamilton, W. L., Leskovec, J., and Jurafsky, D. (2016). Diachronic Word Embeddings Reveal Statistical Laws of
Semantic Change. In Acl 2016, pages 1489–1501.
Jurafsky, D. and Martin, J. H. (2018). Vector Semantics. In Speech and Language Processing, volume Draft of
September 23, 2018.
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013a). Efficient Estimation of Word Representations in Vector
Space. In ICLR Workshop.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., and Dean, J. (2013b). Distributed Representations of Words and
Phrases and their Compositionality. In arXiv:1310.4546 [cs, stat]. arXiv: 1310.4546.
Pennington, J., Socher, R., and Manning, C. D. (2014). GloVe: Global Vectors for Word Representation. In
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages
1532–1543.
Řehůřek, R. and Sojka, P. (2010). Software Framework for Topic Modelling with Large Corpora. In Proceedings of
the LREC 2010 Workshop on New Challenges for NLP Frameworks, pages 45–50, Valletta, Malta. ELRA.
Tissier, J., Gravier, C., and Habrard, A. (2017). Dict2vec: Learning Word Embeddings using Lexical Dictionaries.
In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 254–263,
Copenhagen, Denmark.
23Vous pouvez aussi lire

















































